So much worse
Hyplus目录
1 Pt I
1.1 3D打印技术
平时理论,最后1节课实地操作(11月10日;自行准备建模)
- 模型:手机扩音器
课程论文:结合自身研究方向+3D建模(或感兴趣的点);<1000字;11.11之前提交(格式;打印)。
课程章节(或实验、案例课等)名称与内容
- 第一章 绪论
- 1.1 3D打印概述、发展历史、现状分析及应用领域
- 第二章 3D打印工艺和原理
- 2.1 3D打印工艺的分类
- 2.2 材料挤出工艺
- 2.3 粘结剂喷射成型工艺
- 2.4 光固化成型工艺
- 2.5 粉床熔融工艺
- 2.6 定向能量沉积成型工艺
- 2.7 其他工艺
熔融沉积成型(FDM)技术
打印原理:半流态化的打印材料固化
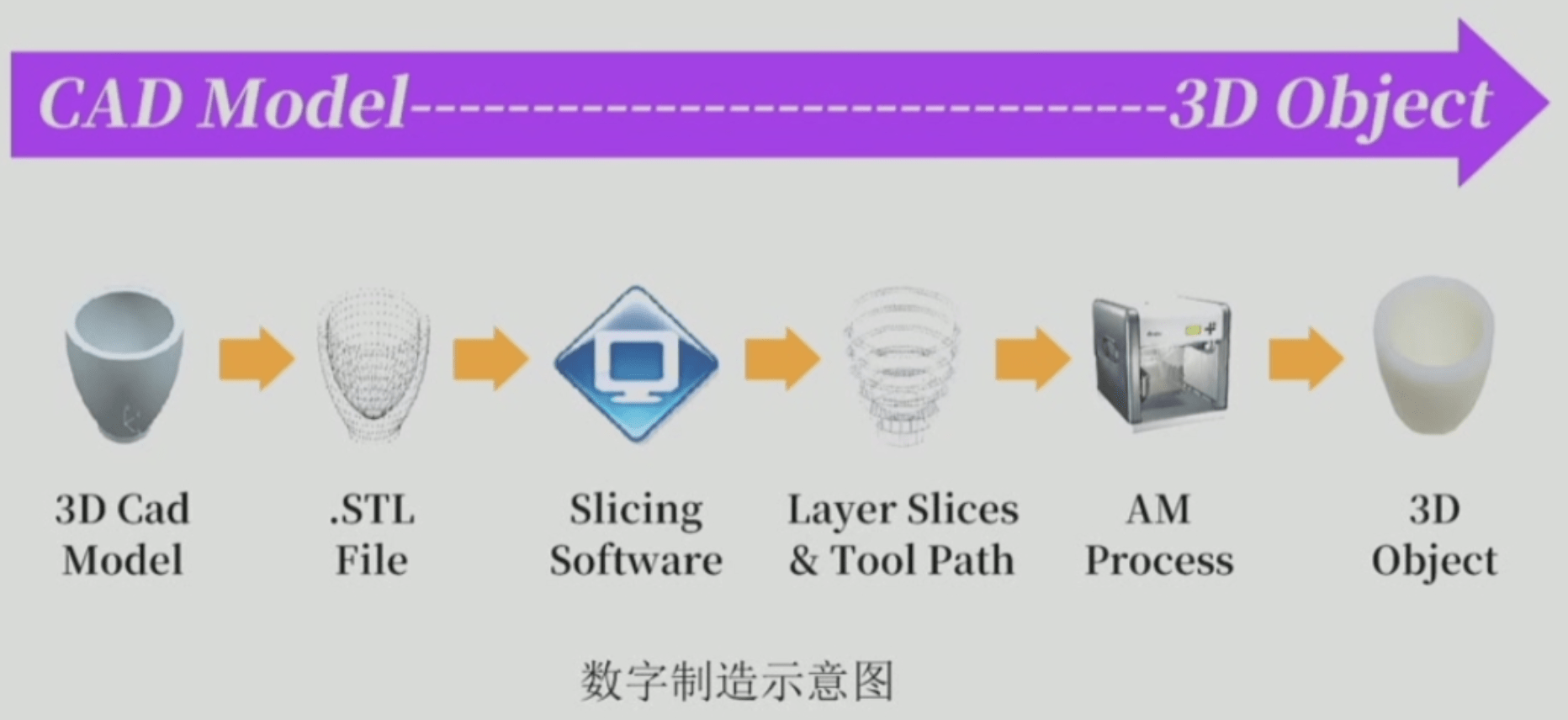
打印流程:建模 → STL文件数据转换 → 分层切片、加入支撑 → 加热/挤出成型 → 后处理 → 打印成品
分类:- 气动式
- 活塞式
- 螺杆式
- 第三章 房屋建筑领域的3D打印
- 3.1 工艺选用及原理
- 3.2 房屋建筑应用案例
- 第四章 景观公建领域的3D打印
- 4.1 工艺选用及原理
- 4.2 景观公建应用案例
- 第五章 隧道岩土及其他领域的3D打印
- 5.1 工艺选用及原理
- 5.2 隧道岩土应用案例
- 5.3 工艺选用及原理
- 5.4 其他领域应用案例
参考资源
参考书:
[1]袁建军等.《3D打印原理与3D打印材料》[M].北京:化学工业出版社,2021.
[2] 陈继民等.《3D打印技术概论》[M].北京:化学工业出版社,2020.
[3]汤慧萍等.《3D打印金属材料》[M].北京:化学工业出版社,2020.
[4]闫春泽等.《3D打印聚合物材料》[M].北京:化学工业出版社,2020.
[5]沈晓东等.《3D打印无机非金属材料》[M].北京:化学工业出版社,2020.
[6]李涤尘等.《光固化增材制造技术》[M].北京:国防工业出版社,2020.
[7]张少军等.《3D打印建筑》[M].北京:中国电力出版社,2018.
[8]马国伟等.《水泥基材料3D打印关键技术》[M].北京:中国建材工业出版社,2020.
[9] Sanjay Kumar. 《Additive Manufacturing Processes》[M].瑞士:Springer出版社,2020.
网络资源:
- 公众号:南极熊3D打印、3D部落、3D科学谷
- 视频:bilibili // ??
3D打印过程
1.2 高级数据库技术
论文(要求详见文档)+ ppt(8分钟pre)
old af ppt/tech; litly no resp; shitty arragement for enhanc.; 4 cls wut; still can be much worse;
1.3 大数据处理关键技术与应用
期末课程汇报70%,平时讨论30%,旷课一次扣2分
课堂展示(30分钟):
- 研读2篇论文并分享(复现结果更佳)
- 要求为22年至今的CCF-A类会议/期刊论文
综述(CCF-A、B会议/期刊或中科院1区的期刊):
- Time Series
- LLMs
- Graph Neural Networks
- Temporal Graph
- Anomaly Detection
- Graph Transformers
- Ranking and Retrieval
论文邮件提交:jinch@hzcu.edu.cn
要求:
- 按照软件学报综述编写,细化研究范围
- 中间讨论两次,分别为第5、10周
- 按提供的实例,按主题开发相关代码
- 准备PPT
大数据与大数据思维
科学研究的四个范式:
- 第一范式:实验归纳(伽利略斜塔实验)
- 第二范式:模型推演(牛顿力学、电磁学)
- 第三范式:仿真模拟(ENIAC、天气模拟)
- 第四范式:基于数据的科学发现(大数据推理)
决策分析观念的改变:
- 传统决策:抽样数据、局部数据和片面数据,经验、假设和价值观
- 大数据决策:要全量数据不要抽样,要决策效率不要绝对精确,要相关不要因果
- 分析过去,提醒现在,展望未来
大数据生态和Hadoop
Hadoop是Apache旗下的一个开源分布式计算平台,基于Java语言开发,核心是HDFS(Hadoop distributed File System)和MapReduce。
Hadoop的特性:
- 高可靠性
- 高效性
- 高可扩展性
- 高容错性
- 成本低
- 运行在Linux平台上
- 支持多种编程语言
Spark是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。特点:
- 运行速度快,使用DAG执行引擎
- 容易使用,支持多种语言进行交互式编程
- 通用性:提供了包括SQL查询、流式计算、机器学习和图算法组件等技术栈
- 运行模式多样:可运行于Hadoop中,也可运行于各种云环境中
Apache三大分布式计算系统开源项目:Hadoop、Spark、Strom
Scala是一门线代的多范式编程语言,运行于Java平台(JVM),并兼容现有的Java程序。特性:
- 具备强大的并发性,支持函数式编程,可以更好地会吃分布式系统
- 语法简洁
- 兼容Java,运行速度快,且能融合到Hadoop生态圈中
分布式文件系统HDFS
分布式文件系统把文件存储到多个计算机节点上。
分布式文件系统的结构:
- 主节点(Master Node)——名称节点(NameNode):存储元数据,存于内存
- 从节点(Slave Node)——数据节点(DataNode):存储文件内容,存于硬盘
HDFS要实现的目标:
- 兼容廉价的硬件设备
- 流数据读写
- 大数据集
- 简单的文件模型
- 强大的跨平台兼容性
HDFS的局限性:
- 不适合低延迟数据访问
- 无法高效存储大量小文件
- 不支持多用户写入及任意修改文件
HDFS采用抽象的块概念。好处:
- 支持大规模文件存储:文件以块为单位进行存储
- 简化系统设计
- 适合数据备份
NameNode负责管理HDFS的命名空间(Namespace),保存了两个核心的数据结构——FsImage、EditLog
- FsImage用于维护文件树以及文件树中所有的文件和文件夹的元数据
- EditLog(操作日志文件)记录了所有针对文件的增删改操作
第二名称结点(SecondaryNameNode)用于保存NameNode中对HDFS元数据信息的备份。
DataNode是HDFS的工作节点。HDFS采用主从(Master/Slave)结构模型,一个HDFS集群包括一个NameNode和若干个DataNode。
HDFS的命名空间包含目录、文件和块。在整个HDFS集群中只有一个命名空间,且只有唯一一个NameNode。
客户端是用户操作HDFS的最常用的方式。
HDFS采用了多副本方式进行冗余数据保存。优点:
- 加快数据传输速度
- 容易检查数据错误
- 保证数据可靠性
分布式并行计算框架MapReduce
Map:映射
Reduce:化简
MapReduce的体系结构:
- Client:提交到JobTracker
- JobTracker:监控TaskTracker与Job,并将信息告知TaskScheduler
分布式数据库HBase
BigTable是一个分布式存储系统,利用MapReduce来处理海量数据。使用分布式文件系统GFS作为底层数据存储,采用Chubby提供协同管理服务。
HBases是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是BigTable的开源实现,主要用于存储非结构化和半结构化的松散数据,其目标是处理非常庞大(10亿+)的表。
优化方法:
- InMemory
- Max Version
- Time to Live
图数据模型
图模型
图数据库
图数据模型
- 有向标记图:G、G+、GraphLog、GOOD、OEM
- 嵌套图:
- 超图
- 属性图:Neo4j
- 图查询语言:Gremlin、Cypher、PGQL、GSQL、nGQL
- RDF(资源描述框架):W3C、OWL
图查询语言
关系型数据库
NoSQL数据库
Cypher语法使用
属性图包含三种元素:点(Node)、边(Edge)、属性(Properties)
Faggot
same jits as above; more jits from jitter; actual prac? gtfoh; second worst cls ever exists
1.4 高级软件工程
课堂报告:40min
Survey for one research point
挑选一个智能软件工程中的热门研究点,寻找近5年来的知名国际会议、期刊(CCF-A和CCF-B)上发表的相关论文,写一篇综述论文(8页双栏)。
会议双栏格式,推荐使用overleaf进行排版撰写,参考附件;
最后提交pdf格式文件;
页数:双栏的不少于8页,单栏不少于15页;
中英文均可。
Introduction
SE Challenges & Problems:
- Costs much resources
- Plagued with bugs
- Many other challenges
Bug: an error, flaw, failure or fault in program
Debug: the process of finding and fixing bugs
Goals of Software Testingand Bug Finding:
- Test adequacy measurement
- Test adequacy improvement
- Test selection
- Identification of software bugs
Data Source Artifacts:
- Source Code
- Google code: http://code.google.com/ (archive)
- Github: https://github.com/
- Execution Trace
- Development History
- CVS - Version per file
- SVN - Version per snapshot
- Git - Distributed
- Code Review: Systematic examination; find and fix mistakes
- Bug Reports
- BugZilla: http://www.bugzilla.org/
Example site: https://bugzilla.mozilla.org/ - JIRA: http://www.atlassian.com/software/jira/
Example site: https://issues.apache.org/jira/browse/WW
- BugZilla: http://www.bugzilla.org/
- Developer Activities
- GitHub
- Software Forums
- StackOverflow:http://stackoverflow.com/
- StackExchange:https://stackexchange.com/sites
- Reddit, Programming:https://www.reddit.com/r/programming/
- Quora:https://www.quora.com/
- Software Microblogs
- Operations
Data Mining for SE
Pattern Mining
Recommended Technique: Association Rules
- Support(支持度)
- Confidence(置信度)
Applications:
- Allatin: Mining Alternating Patterns for Defect Detection
- And/Or/Xor/Combo Patterns
Clustering
- Techniques
- k-Means
k-medolds- Hierarchical Clustering:
- AGNES (Agglomerative Nesting)
DIANA (Divisive Analysis)
Classification
- SVM
- kNN
- ……
NLP for SE
Text in SE:
- Real text
- Issue/bug reports
- Documents
- Q&A disccusions
- Comments
- Code
Text Preprocessing:
- Tokenization
- Stop-word Removal
- Normalization
- Steeming
Code Preprocessing:
- Parsing
- Identifier Extraction
- Identifier Tokenization
Vector Space Modeling (VSM)
Software Document Generation
Code Comprehension
……
Call Graph
wow, faggot again
se for mi ass, what r u drugging, smoking jit? brainrot scammer, piece of jit; y even live, faggot? worst cls ever exists
ok, rewatched ur jit, and it became even jittier, faggot, se ur cum, retard; gtfoh;
1.5 算法分析与设计(图算法)
参考教材:
- 【Zotero】图深度学习(马耀、汤继良)
平时总评:50%(分组 pre)
期末论文:50%(文献综述)
- 应用综述:
- Social Network Analysis
- Recommendation System
- NLP
- Computer Composition
- Computer Vision
- Biomedical and Healthcare
- Fraud Detection
- Traffic Analysis and Automonus Vehicles
- 技术综述:
- Graph Convolutional Network (GCN)
- Graph Attention Network (GAT)
- GraphSAGE (Graph Sample and Aggregation)
- Graph Isomorphism Network (GIN)
- Graph Autoencoders
- Dynamic and Temporal Graphs
- Graph Compression and Approximation/Hypergraphs
- Generative AI
图深度学习介绍
图特征提取:图 → 向量
- 特征工程:手动提取(度、中心性…);slow; time consuming
- 特征学习:自动学习——特征选择,表示学习
图表示的学习:
- 数据降维
- 网络嵌入:DeepWalk…
- 图深度学习
图嵌入(Embedding):图域 \xrightarrow{映射} 嵌入域;信息提取器、重构器 → 优化目标
简单图上的图嵌入:
- 保留结点共现
- 保留结构角色
- 保留节点状态
- 保留社区结构
图神经网络:邻接矩阵 \xrightarrow{图滤波} 节点表示 \xrightarrow{图池化} 图表示
图滤波:A,X\rightarrow A,X_f(邻接矩阵不变,特征向量变化)
- 基于谱的图滤波
- 基于空间的图滤波
图池化:A,X\rightarrow A_p,X_p(邻接矩阵和特征向量均变化;维度改变)
- 平面图池化
- 层次图池化
鲁棒性、可拓展性……
图深度学习的应用:
- NLP:语义角色标注、神经机器翻译、关系抽取、多跳回答任务
- 数据挖掘:社会影响力预测、社交表征学习、政治观点预测
- 推荐系统:用户购买历史图、社交网络、知识图谱
- 计算机视觉:骨架图、标签关系图、点云
- 生物医疗:分子图、药物蛋白质关系图
- 可表达性:Weisfeiler-Lehman图同构检验
研究前沿:
- 图上的自监督学习
- 可解释性(样本级、模型级)
图论基础
\mathcal{G} =\{\mathcal{V} ,\mathcal{E} \}
邻接矩阵\mathbf{A}
度d(v_i):与v_i节点相连的点的个数
节点的邻域\mathcal{N} (v_i):与v_i节点相连的点的集合
途径(Walk):节点和边的交替序列;长度为边的数量
- 迹(Trail):边各不相同的途径
- 路(Path):节点各不相同的途径
连通性、连通图
最短路:连接两个节点的长度最小的路,其长度称为两点间的距离
图的直径:图中最长的最短路
节点的中心性:用来衡量节点在图上的重要程度
度中心性:利用节点的度来衡量节点的中心性:
c_d(v_i)=d(v_i)=\sum\limits_{j=1}^N \mathbf{A}_{i,j}特征向量中心性:衡量节点的中心性时同时考虑邻居的中心性
c_e(v_i)=\frac1{\lambda}\sum\limits_{j=1}^N \mathbf{A}_{i,j} c_e(v_j) \\
\mathbf{A}\mathbf{c}_e=\lambda \mathbf{c}_eKatz中心性:特征向量中心性的变种
c_k(v_i)=\alpha\sum\limits_{j=1}^N \mathbf{A}_{i,j} c_e(v_j) +\beta\\
(\mathbf{I}-\mathbf{\alpha}\mathbf{A})\mathbf{c}_k=\mathbf{\beta}复杂图:
- 异构图
- 二分图
- 多维图
- 符号图
- 超图
- 动态图
深度学习基础
统计机器学习MOOC课件:https://pan.baidu.com/s/144xKEOtcS__sBmjjvaMPJQ?pwd=ypc3
前馈神经网络
卷积神经网络
- 卷积层主要有三个重要特点,包括稀疏连接、参数共享和等变表示。
……
kinda scammed, but, whatever, just don be jit
1.6 人工智能算法与系统
平时50%,考勤10%,期末综合测评40%
参考资料:【Zotero】人工智能导论:模型与算法 (吴飞)
基本概念
证明算数公理的相容性:
- 完备性
- 一致性
- 可判定性
| Traditional AI | Artificial Genral Intelligence |
|---|---|
| learning by data and rules | learning to learn |
人工智能主流方法:
- 符号主义人工智能(Symbolic AI)
- 符号逻辑表示下的推理(用规则教) -> 知识图谱
- 逻辑推理
- 优势:与人类逻辑推理相似,解释性强
- 不足:难以构建晚辈的知识规则库
- 联结主义
- 数据驱动的机器学习,挖掘数据所蕴含的内在模式(用大数据学)
- 机器挖掘得到的视觉模式
- 优势:直接从数据中学
- 不足:以深度学习为例;依赖于数据,解释性不强
- 行为主义
- 从经验中的策略学习——用问题引导(反馈牵引)
- 优势:从经验中进行能力的持续学习
- 不足:非穷举式搜索而需更好策略
三种方法综合利用
AlphaFold 技术交叉和学科交叉下的感知和决策:
- 深度学习
- 强化学习
- 蒙特卡洛树搜索
- 图神经网络
- 注意力模型
- 物理建模
人工智能应具备的能力:
- 具备视觉感知和语言交流的能力
- 具备推理与问题求解能力
- 具备协同控制能力
- 具备遵守伦理道德能力
- 具备从数据中进行归纳总结的能力
y not swap w/ ml basic of Pt II? almost scammer;
1.7 工程前沿技术讲座
每次讲座结束一周内,提交一份该主题综述报告,字数不少于2000字。
每次讲座结束一周后进入互评流程,并在互评周内完成互评。
互评满分100,请按自己的知识标准进行互评。
1 大数据可视化
讲座内容:
大数据可视化是将海量复杂数据通过直观的图形和图像呈现,以帮助决策者快速理解数据趋势和规律的关键技术。在当前信息化和数字化快速发展的背景下,大数据可视化作为数据分析的重要工具,广泛应用于金融、医疗、交通、营销等各个领域。本次讲座将深入探讨大数据可视化的基本概念、技术原理和方法,并分享行业应用案例,揭示其在数据洞察和决策支持中的重要作用。
脑神经纤维束可视化
图神经网络
国画大数据——赏析、分析、管理系统
echarts
CodeGeex
可视化应用:智慧城市、体育数据分析
2 可归因时变预后建模方法及临床应用
讲座内容:
- 研究生期间科研成长经历分享(如何过好研究生阶段)
- 学生指导过程中的感悟分享(如何让学生更好成长)
- 时变预后建模方法的专题报
人工智能辅助重大疾病诊断
- 辅助疾病诊断,提升诊断效率
- 探索疾病规律,发掘标记特征
预后(Prognosis)
预后建模
预后模型性能评价:td-CI、td-AUC
Deep Prognosis
*3 讲座三
请就本次讲座涉及的相关领域,就其中2个主题方向提交一份该主题综述报告,字数不少于2000字。讲座结束一周后进入同学互评流程,并在互评周内完成互评互评满分100分,请同学按照自己的知识标准进行互评。
主题一:水下机器人关键技术
主讲人:何诗鸣老师
内容:水下机器人是可潜入水中代替或辅助人类进行水下极限作业的机器人。报告主要介绍水下机器人的四点关键技术:(1)自主控制,主要包括运动控制、传感器数据感知、自主路径规划与避障等技术;(2)自主对接与回收,即利用水下基站进行自动能源补给和数据交换;(3)水下数据链通信,包括水声信道编码、自适应均衡以及时间反转通信等;(4)集群协同技术,包括信息共享能力、协同导航能力、任务动态分配能力、编队协同能力。最后介绍未来水下机器人的发展趋势。
水下航行器
海人一号
航行器系统设计
- 四旋翼式水下航行器
- 八爪鱼水下航行器
输出重定义方法
- 姿态敏感轨迹跟踪
主题二:“双碳”背景下新型电力系统关键技术与发展趋势
主讲人:晶颜秉老师
内容:聚焦于'双碳'战略下新型电力系统的关键技术演变及未来趋势。深入解析了双碳目标如何驱动能源体系向绿色低碳转型,阐述了新型电力系统如何以清洁低碳灵活高效为特征,实现高比例可再生能源接入与多能互补。同时,直面了电力转型升级带来的技术挑战,如电力供应保障、系统平衡调节、安全稳定运行、整体供电成本等问题,并展望了通过广域协调、智能感知等手段应对挑战的途径,旨在促进社会各界对新型电力系统发展的理解与关注。
4 边缘计算技术导论
随着传感云边缘设备在用户和数据源附近的广泛部署,提供高质量的智能服务成为解决人工智能技术“最后一公里”难题的关键。然而,传感云环境中数据动态多样,端侧设备资源受限且高度异构,这为边缘智能服务的模型选择、适配优化和持续学习等环节带来了巨大挑战。本讲座将深入探讨如何在边缘智能服务中有效进行模型选用,重点关注以下几个核心问题。首先,介绍模型-服务-设备三元空间中预训练模型的选择与增强方法。接着,探讨端侧硬件特性感知的模型适配优化技术,旨在最大限度地挖掘设备资源,提高智能服务的整体质量。随后,介绍成本效益最优的边缘智能模型持续学习方法,能够及时应对传感云环境中数据分布和环境变化,确保服务质量的持续稳定。
5 工业智能机器人研发及设计基础讲座
根据本次讲座内容,对工业机器人未来5-10年的发展趋势和关键技术,提出个人的看法,并列出查阅的相关参考文献。
定位精度(Accuracy)指的是定位值与真实值之间的接近程度,描述的是机器人定位的准确程度。机器人定位高精度意味着机器人定位与实际要求的真实值非常接近,误差小。重复性(Repeatability):指的是在相同条件下机器人重复移动到某个定位时,得到的定位一致性或稳定性。机器人的高重复性意味着多次定位的结果非常接近,误差较小。
重复性与机器人系统的随机误差有关,但不一定意味着定位的准确,一般用来说明机器人的稳定性。精度和重复性都是工业机器人实际应用中很重要的性能指标。精度是系统误差,重复性是随机误差。
6 论“元宇宙”产业发展与典型应用
讲座内容:近年来,“元宇宙”引发科技界、企业界、资本界乃至政府部门的关注,因为它给人们的生产生活带来便利是“大数据”“自媒体”时代所不能比拟的。伴随着5G、数字孪生、区块链等基础设施的完善、智能终端的普及、以及虚拟现实、增强现实、扩展现实、云计算及数字孪生等技术的成熟,人们将迎来“元宇宙”,或者说现已生活在“元宇宙”的雏形中。2021年是元宇亩元年,标志性事件是Facebook把公司名称改为“Meta”,并在财报中披露要对旗下的元宇宙部门投资至少百亿美元。进入2022年,元宇宙大火,但也出现了一定泡沫。在此情况下通过前期积累和项目经验厘清元宇宙的内涵与本质特征、快速发展的驱动力、相关技术与产业链等。
7 先进集成电路技术
讲座内容:
集成电路产业自其诞生以来,便成为了推动现代科技发展的重要力量。随着物联网、人工智能、5G等新兴技术的不断发展和普及,集成电路产业迎来了更加广阔的发展空间。这些新兴技术对高性能、低功耗、高集成度芯片的需求为产业提供了巨大的市场机遇和发展空间。
集成电路产业具有高度的技术密集性和资本密集性,需要持续投入大量的研发资金和人力资源,以推动技术的不断进步和产品的更新换代。同时,由于产业链上下游之间的紧密联系,任何一个环节的突破都可能带动整个产业的升级和发展。芯片技术不断的创新和突破为产业的快速发展提供了源源不断的动力。
纳米级工艺制程、FinFET、GAAFET、三维封装、SOI、高迁移率沟道,先进集成电路技术的持续涌现是提升国家竞争力的关键因素,为相关产业注入了源源不断的活力。
8 多模态预训练模型
……
9 前沿工程技术讲座综述报告
题目:前沿工程技术讲座综述报告——当代科技趋势与应用展望
任务要求:
- 综合运用前沿工程技术讲座中所涉及的内容,撰写一份综述报告,对当代科技趋势和应用进行深入分析和展望。
- 选择2-3个讲座主题,结合具体实例,深入讨论讲座主题的重要性、发展现状以及未来可能的发展方向。
- 近3年中英文参考文献不少于10篇,报告不少于4000字。
评分标准:
- 对主题进行深入的分析和综合运用(20分);
- 结论具有创新性和深度,能够展望未来科技的发展趋势(30分);
- 文章逻辑性强,表达清晰,引用准确(30分);
- 参考文献符合要求(10分);
- 字数符合要求(10分)。
y mix all from diff fields to ur whole ass jit? brainrot arragement; reused crap by mid ppl; fck off;
1.8 研究生论文写作指导
概论
科技论文和其他文体的区别:
- 主题更鲜明、更专业
- 应用科学、基础研究
- 创造性的结论
科技论文特点:
- 科学性
- 创造性
- 理论性
- 实践性
- 可读性:通俗易懂的语言
问题、创意 → 信息检索、分析 → 实验、计算…… → 发表:口头报告、论文、专利 → 同行评价、引用、应用 → 新的问题、发展、延伸……
期刊、专利文献、会议(人工智能四大顶会AAAI、IJCAI、ICML、NIPS,计算机视觉和自然语言为代表的学术会议CVPR、ACL)
总体画面 → 缺失环节、矛盾之处、需要解决的问题
成果发表的重要性:
- 科技论文是成果的重要表现形式
- 撰写科技论文是每一位科研工作者的基本工作
- 毕业
英语撰写的必要性:国际通用语言
- 提高国家或学校的学术地位
- 促进研究工作发展
- 建立信息交流网
中国科技论文发表的现状
- 数量急速增长,第一
- 质量不断提高(影响力),但仍有很大的提升空间
CNS论文:《Cell》、《Nature》、《Science》
论文的本质属性:一种讨论某种问题或研究某种问题的说理文章
科技论文的分类:
- 按照研究方法
- 实验研究报告
- 理论推导、分析
- 设计计算
- 综合论述
- 按照发挥作用
- 学术性论文:向学术性期刊/会议提交
- 技术性论文
- 学位论文:学位申请
- 学士学位论文:从事研究或担负工作的初步能力
- 硕士学位论文:基本上达到发表水平
- 博士学位论文:被视为重要的科技文献
- 其他
学位论文要经过考核和答辩,因此无论是论述还是文献综述,还是介绍实验装置、实验方法都要比较详尽。
学术性或技术性论文是写给同专业的人员看的,应力求简洁。
科技论文的基本框架:
- 摘要(200-400字)、关键词
- 引言
- 正文部分
- 结论
- 参考文献
科技论文写作的目的和意义:
- 是创造、传播、应用、传承知识的形式
- 课题活动、学术会议、撰写论著
- 学术期刊和会议文集是学界知识传承的主要载体
- 大众传媒、专业书籍、科技期刊(技术类、学术类)
- 以规范的表达形式对研究成果进行归纳总结
- 是对作者科研能力的检验与实证
- 提高文献检索能力、文献综合能力、学术批判能力、逻辑思维能力、文字表达能力,以及知识体系建构能力
学术规范:学术积累和创新的各种准则与要求
国内主要的文献检测系统:ROST反剽窃系统、学术不端文献检测系统、CNKI科研诚信管理系统…
科技期刊的评价体系:
- 总被引频次
- 影响因子
- 他引率 = 该刊被其他期刊引用的次数 / 期刊被引用的次数
- 自引率 = 1 - 他引率
- H指数
学术论文的写作方法
文献检索:
- Web of Science
- AAAS
- Springer Nature
- ELSEVIER
- IEEE Xplore
- Wiley Online Library
- Google Scholar + SCIHub
综述检索:Keywords + Review
综述撰写:
- 标题:中文≤25字,英文≤10个单词
- 一般形式:定语(方法、类别、范围、技术路线等描述性词) + 名词(核心内容)
- 摘要:精简,每句话都应有独立的意义
- 第一句:回顾背景
- 第二句:找出科学背景和本文的连接点,或提出科学问题、技术难题(选题意义)
- 第三句:提出主要内容、核心信息和重点工作
- 第四句:点出技术路线,标出创新点、特点等
- 第五句:拓展提升,强调意义
were is 2? idk, in ur ass perchance; bad arragement; no resp at all once again; prac? research ur ass;
1.9 工程伦理
平时成绩10%,随堂测试30%,案例分析60%
(1)简述案例;(2)提炼工厂伦理议题;(3)分析伦理责任
分组汇报:第2周开始,每周2-3组,每组5-6人
课程论文:第9周提交纸质版,无字数要求,结合自己的研究方向选择案例
参考资料:【Zotero】工程伦理(全国工程专业学位研究生教育国家级规划教材)
工程伦理概述
工程教育专业认证
- 工程知识
- 问题分析
- 设计/开发解决方案
- 研究
- 使用现代工具
- 工程与社会
- 环境和可持续发展
- 职业规范
- 个人和团队
- 沟通
- 项目管理
- 终身学习
工程生命周期:计划 → 设计 → 建造 → 使用 → 结束
工程伦理问题:技术、利益、责任、环境
工程中的风险、安全与责任
工程风险的来源
- 技术因素:零部件老化、控制系统失灵、非线性应用
- 环境因素:气候条件、自然灾害
- 人为因素:工程设计者、施工者、操作人员
工程风险的可接受性
- 相对可接受性
- 安全等级的划分(定量描述)
风险评估
伦理责任
……
y even have b-"ppl" to "teach" a-ppl? whats the point of this? 『nO~t O-uaH tEa-CHeaHH---』ok, go f urself, retard;
1.10 数学模型与方法
平时25%,期中作业35%,期末考试40%
平时表现:课堂表现、课堂讨论、翻转讲解
期中作业:讨论至少一位近现代数学家(20世纪以来),内容关于概率统计、随机过程思想、近现代数学理论与公式的论文,不少于8页,参考文献不少于10篇。
考核形式:考试-闭卷
参考资料:
- 【Zotero】概率论与数理统计 盛骤 浙江大学
- 概率论与数理统计(本站资源)
King faggot of all faggots; worst human beings ever exist; ZERO resp, wrong ass ans all the places; scammer KING, ppl need jet and it "teached" jit; go f urself;『nOoOoO---- NoOooO~tT Ooo-uaaH tEa-CHUUUUeaHH---』ok, both go f urself, retards;
2 Pt II
2.1 大规模语言模型算法与应用
team
more in dingding
2.2 高性能计算
考核方式:
- 课程作业(4~5次)+考勤 —— 30%
- 高性能计算领域的研究综述(5000字以上,近五年参考文献50篇) —— 70%
要求:按时(下次课前一天晚上10点之前)、按量、按质
参考书籍:
- 托马斯等著,黄智濒等译,高性能计算:现代系统与应用实践
- 陈国良(院士). 并行计算:结构·算法·编程(第3版). 高教社
- Ananth等著,张武等译. 并行计算导论. 机械工业出版社
在线资源:
- CMU公开课:http://15418.courses.cs.cmu.edu/spring2016/lectures
- UC Berkeley讲义:https://people.eecs.berkeley.edu/~culler/cs258-s99/
- OpenMP:https://www.openmp.org/
- MPI:https://www.mpi-forum.org/
2.3 深度学习应用开发与实践
coding
y not swap with that jit? so f basic, peak for Pt I, clown for Pt II
2.4 数据采集与可视化
WIP