Redis的使用场景:
- 缓存:穿透、击穿、雪崩;双写一致、持久化;数据过期、淘汰策略
- 分布式锁:setnx、Redisson
- 计数器、保存token、消息队列、延迟队列:数据类型
其他题:集群(主从、哨兵、集群)、事务、Redis为什么快
1 数据类型
Redis是典型的键值型数据库,不同数据类型其key结构一致,value有所差异。
1.1 Redis五大数据类型
常见的类型有String、Hash、List、Set、SortedSet等,而基于这5种基本数据类型,Redis又拓展了几种拓展类型,例如BitMap、 HyperLogLog、Geo等。
- String:Redis中最常见的数据类型,value与key一样均为Redis自定义的字符串结构,称为SDS。
- 在保存数字、小字符串时会采用INT和EMBSTR编码,内存结构紧凑,只需申请一次内存分配,效率更高,更节省内存。
- 超过44字节的大字符串则采用RAW编码,申请额外的SDS空间,需要两次内存分配,效率较低,内存占用也较高,但最大不超过512mb,因此建议单个value尽量不要超过44字节。
- String类型常作计数器、简单数据存储等。复杂数据建议采用其它数据结构。
- Hash:value与Java中的HashMap类似,为一个key-value结构。若某对象需要被Redis缓存,并且将来可能会有部分修改,建议采用Hash结构来存储该对象的每一个字段和字段值,不建议作为JSON字符串存储为String类型,因为Hash结构的每一个字段都可以单独做修改,而String的JSON串必须整体覆盖。
- 与Java中的HashMap不同的是,Redis中的Hash底层采用了渐进式rehash的算法,在做rehash时会创建一个新的HashTable,每次操作元素时移动一部分数据,当所有数据迁移完成时,再用新的HashTable代替旧的,避免了因为rehash导致的阻塞,因此性能更高。
- List:value类型可看做为一个双端链表,提供了一些便于从首尾操作元素的命令。
- 为了节省内存空间,底层采用了ZipList(压缩列表)作为基础存储,当压缩列表数据达到阈值(512)则会创建新的压缩列表。每个压缩列表作为一个双端链表的一个节点,最终形成一个QuickList结构,其结构与一般的双端链表不同,可对中间不常用的ZipList节点做压缩以节省内存。
- List结构常用于模拟队列,实现任务排队等功能。
- Set:value与Java中的Set类似,元素不可重复。Redis提供了求交集、并集等命令,以此实现例如好友列表、共同好友等功能。
- 当存储元素为整数时,其底层默认采用IntSet结构,可视为一个有序数组,结构紧凑,效率较高。而若元素不是整数,或元素量超过阈值(512)则会转为Hash表结构,内存占用大幅增加。因此在使用Set结构时尽量采用数组存储,例如数值类型的id,并且元素数量尽量不超过阈值(512),避免出现BigKey。
- SortedSet(ZSet):value为一个有序的Set集合,元素唯一,并且按指定的score值排序。因此常用于排行榜功能。
- 底层利用Hash表保证元素的唯一性,利用跳表(SkipList,见后述)来保证元素的有序性,因此数据可能会重复存储,内存占用较高,是一种典型的以空间换时间的设计。不建议在SortedSet中放入过多数据。
1.2 跳表(SkipList)
跳表(SkipList)是一种链表,但与传统的链表相比有以下几点差异:
- 结合了链表和二分查找的思想
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同
- 查找时从顶层向下,不断缩小搜索范围
- 整个查询的复杂度
O(\log n

Redis数据类型Sorted Set使用跳表作为其中一种数据结构。
2 数据持久化策略 ⭐️
在Redis中提供了RDB、AOF两种数据持久化方式,两种方式的对比如下表所示:
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘I/O资源 但AOF重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高 |
实际使用时通常结合RDB+AOF进行持久化。
2.1 RDB
RDB(Redis Database Backup file,Redis数据备份文件,Redis数据快照):定期将Redis中的数据生成的快照同步到磁盘等介质上,磁盘上保存的是Redis的内存快照。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
- 优点:数据文件的大小相比于AOF较小;使用RDB进行数据恢复速度较快。
- 缺点:比较耗时,存在丢失数据的风险。
主动备份命令:
# redis-cli
save # 由Redis主进程执行RDB,会阻塞所有命令
bgsave # 开启子进程执行RDB,避免主进程受到影响Redis内部有触发RDB的机制,可在redis.conf文件中找到,格式如下:
save 900 1 # 900秒内,若至少有1个key被修改,则执行bgsave
save 300 10
save 60 10000bgsave的执行原理:开始时fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入RDB文件。fork采用copy-on-write技术:
- 当主进程执行读操作时,访问共享内存
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作

2.2 AOF
AOF(Append Only File,追加文件):将Redis所执行过的所有写命令记录在AOF文件里,下次Redis重启时只需要执行指令即可。
- 优点:数据丢失的风险大大降低。
- 缺点:数据文件的大小相比于RDB较大;使用AOF文件进行数据恢复时速度较慢。

AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
# 是否开启AOF功能,默认为no
appendonly yes
# AOF文件名
appendfilename "appendonly.aof"AOF命令记录的频率亦可在redis.conf配置文件中设置:
# 每执行一次写命令,立即记录至AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,之后每隔1秒将缓冲区数据写入AOF文件【默认】
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no| 频率配置项 | 刷盘时机 | 优点 | 缺点 |
|---|---|---|---|
always |
同步刷盘 | 可靠性高,几乎不丢数据 | 性能影响大 |
everysec |
每秒刷盘 | 性能适中【综合最优】 | 最多丢失1秒数据 |
no |
操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量数据 |
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。

Redis亦会在触发阈值时自动重写AOF文件,阈值可在redis.conf配置文件中配置:
# AOF文件比上次文件增长超过多少百分比后触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb3 主从和集群
Redis提供的集群方案共有三种:主从复制、哨兵模式、分片集群
一般部分服务做缓存用的Redis直接做主从(1主1从)加哨兵即可。单节点不超过10G内存,若Redis内存不足则可以给不同服务分配独立的Redis主从节点。
尽量不做分片集群,原因如下:
- 维护麻烦
- 集群之间的心跳检测和数据通信会消耗大量的网络带宽
- 集群插槽分配不均和key的分批容易导致数据倾斜
- 客户端的route会有性能损耗
- 集群模式下无法使用lua脚本、事务
其他扩展:
- 一般企业中redis存储超过100GB是极少见的,一般只存热点数据。
- 极端情况下,可以设置较大的内存。以阿里云为主,购买内存型服务器,目前最大为2048GB。
保证Redis高并发高可用的方法:主从+哨兵;集群。
3.1 主从复制、主从同步
主从复制(Master/Slave Replication):读写分离——主库写操作,从库读操作。
特点:
- 保证高可用性
- 实现故障转移需要手动实现
- 无法实现海量数据存储

Replication ID(replid)是数据集的标记,ID一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid。
偏移量(offset)随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。 如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
主从全量同步(第一次同步):
- 从节点执行
replicaof命令建立连接,向主节点发送psync命令,发送自己的replid(Replication ID)和offset给主节点 - 主节点判断从节点的
replid与自己的是否一致,若不一致说明是第一次同步,需要做全量同步,主节点返回自己的replid给从节点 - 主节点开始执行
bgsave,生成RDB文件 - 主节点发送RDB文件给从节点,在发送的过程中,记录RDB期间的所有新命令至
repl_baklog - 从节点接收文件,清空本地数据,加载RDB文件中的数据
- 同步过程中,主节点接收到的新命令写入从节点的写缓冲区(
repl_buffer) - 从节点接收到缓冲区数据后写入本地,并记录最新数据对应的
offset

主从增量同步(slave重启或后期数据变化):
- 主节点会不断将自己接收到的命令记录在
repl_baklog中,并修改offset - 从节点向主节点发送
psync命令,发送自己的replid和offset - 主节点判断
replid和offset与从节点是否一致,若replid一致,说明是增量同步。然后判断offset是否一致,若从节点的offset小于主节点的offset,并且在repl_baklog中能找到对应数据,则将offset之间相差的数据发送给从节点。 - 从节点接收到数据后写入本地,修改自己的
offset与主节点一致。

增量同步的风险:repl_baklog存在大小上限,写满后会覆盖最早的数据。若slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,只能再次全量同步。(repl_baklog可以在配置文件中修改存储大小)
3.2 哨兵模式
哨兵(Sentinel)模式可实现主从集群的自动故障恢复。
特点:
- 保证高可用性
- 可以实现自动化的故障转移
- 无法实现海量数据存储

结构与作用:
- 服务状态监控:Sentinel会不断检查master和slave是否按预期工作。
- 原理:心跳机制。每隔1秒向集群的每个实例发送ping命令:
- 主观下线:如果某Sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
- 客观下线:若超过指定数量(
quorum)的Sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
- 哨兵选主原则:
- 首先判断master与slave节点断开时间长短,若超过指定值则排除该从节点。
- 然后判断slave节点的
slave-priority值,越小优先级越高。 - 若
slave-prority相同,则判断slave节点的offset值,越大优先级越高。 - 最后判断slave节点的运行ID大小,越小优先级越高。
- 可能会发生脑裂问题,详见集群脑裂
- 原理:心跳机制。每隔1秒向集群的每个实例发送ping命令:
- 自动故障恢复:如果master故障,Sentine会将一个slave提升为master。当故障实例恢复后继续以新的master为主
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
3.3 分片集群
分片集群(Cluster)解决了主从和哨兵无法处理的海量数据存储、高并发写问题。
特点:
- 保证高可用性
- 可以实现自动化的故障转移
- 可以实现海量数据存储

分片集群的作用:
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个slave节点
- master之间通过ping监测彼此健康状态
- 客户端请求可以访问任意解
分片集群中数据存取规则:Redis集群引入了哈希槽的概念。Redis集群有16384个哈希槽,每个key通过CRC16校验(根据key的有效部分计算哈希值:例如对于set {aaa}name kina,有效部分为aaa,若无{aaa}则直接以key本身为有效部分)后对16384取模来决定放置哪个槽,集群的每个节点负责一部分Hash槽。
下图为存值的流程,取值的流程与之类似:

3.4 集群脑裂
Redis集群(在哨兵模式下)可能由于网络等原因发生集群脑裂(Split-Brain):由于Redis的Master、Salve节点与Sentinel处于不同的网络分区,使得Sentinel无法根据心跳感知到Master,故通过选举的方式提升了一个Salve为Master,由此就存在两个Master(如同大脑分裂了一样),导致客户端还在Old Master处写入数据,新节点无法同步数据。当网络恢复后,Sentinel会将Old Master降为Salve,此时再从新Master同步数据,会导致大量数据丢失。
正常情况:

发生脑裂时的情况:

网络恢复后的情况:

解决方案:Redis中配置以下两个参数——
min-replicas-to-write 1:设置最少的salve节点为1个min-replicas-max-lag 5:设置数据复制和同步的延迟不能超过5秒
配置了这两个参数后,如果发生脑裂,原Master会在客户端写入操作时拒绝请求,由此可以避免大量数据丢失。
4 缓存使用场景 ⭐️
加入缓存后的数据查询流程:

通常在用户行为数据、热点文章、热点数据等场景使用缓存。
《缓存三兄弟》
穿透无中生有key,布隆过滤null隔离。
缓存击穿过期key,锁与非期解难题。
雪崩大量过期key,过期时间要随机。
面试必考三兄弟,可用限流来保底。
4.1 缓存穿透与布隆过滤器
缓存穿透(Cache Penetration):在查询特定数据时,若在存储层未能找到该数据(该数据不存在),则不会将其写入缓存。这种情况导致每次请求都必须直接查询数据库,可能引发数据库负载过重甚至崩溃的风险。
【例】一个GET请求api/news/getById/1

解决方案:
- 缓存空数据:对于查询返回的数据为空的情况,仍然将该空结果进行缓存,但应设置较短的过期时间。(
{key:1,value:null})- 优点:简单
- 缺点:消耗内存,可能会发生不一致问题
- 布隆过滤器(Bloom Filter):由布隆于1970年提出的一种概率性数据结构,主要由一个位图和一系列哈希函数组成,主要功能为用于高效地检索一个元素是否存在于某个集合中。将所有可能存在的数据哈希到一个足够大的位图中,从而能够有效拦截一定不存在的数据,避免不必要的数据库查询。
- 优点:内存占用较少,没有多余的key
- 缺点:实现复杂,存在误判

Bitmap(位图)相当于一个以位(bit)为单位的数组,数组中每个单元只能存储二进制数0或1。

【例】添加元素:将商品id为1(id1)的数据存储至布隆过滤器
- 存储数据:通过多个Hash函数获取Hash值,根据Hash计算数组对应位置,将其改为1
- 查询数据:使用相同的Hash函数获取Hash值,单端对应位置是否都为1

由于哈希函数可能存在冲突,无法完全确认其存在性,可能会出现误判。如下图所示,假设在添加完元素id1和id2后,布隆过滤器中的数据存储方式如上图所示。此时,如果要判断元素id3是否存在于布隆过滤器中,根据上述判断规则,可能会得出该元素存在的结论。然而,实际上id3并未被添加到布隆过滤器中,这种情况即属于误判:

误判率:位数组越小,误判率越高;位数组越大,误判率越低。然而增大位数组的同时也会导致内存消耗的增加。
关于删除元素:布隆过滤器不支持删除操作,因为一旦允许删除,可能会影响对元素不存在的判断结果。这是由于布隆过滤器的设计特性,删除操作可能导致原本标记为存在的元素被错误地识别为不存在。
在Redis的框架Redisson中提供了布隆过滤器的实现,使用方式如下,首先需在pom.xml文件中引入依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>${redisson.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>4.2 缓存击穿
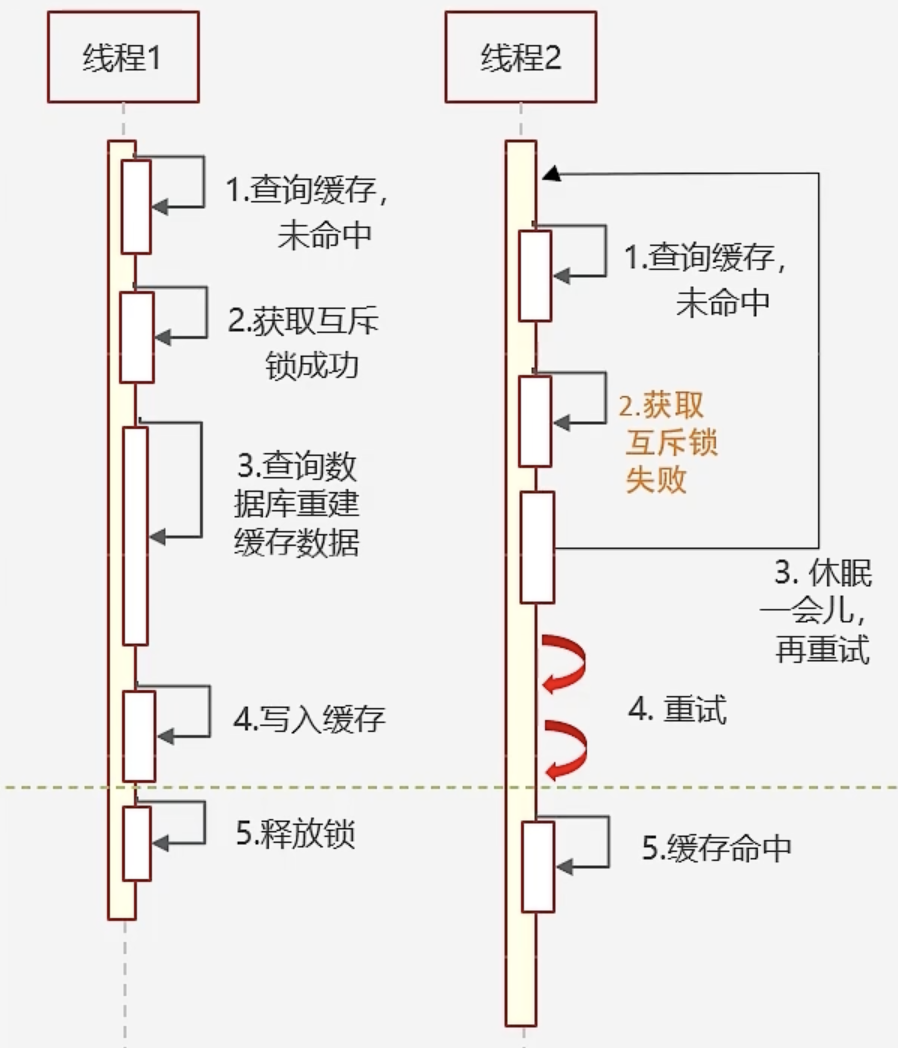
缓存击穿(Cache Breakdown):当某个设置了过期时间的缓存key在特定时间点过期时,恰好此时有大量并发请求针对该键发起。由于这些请求发现缓存已过期,通常会直接从后端数据库加载数据并重新设置到缓存中。在这种情况下,瞬间涌入的大量并发请求可能会导致数据库承受过大的压力,从而造成性能下降或崩溃。

解决方案:
- 使用互斥锁:在缓存失效时,不立即从数据库加载数据(
load db),而是首先使用如Redis的SETNX命令设置一个互斥锁。如果锁设置成功,则执行数据库加载操作并更新缓存;如果锁设置失败,则重试获取(get)缓存的数据。- 优点:没有额外的内存消耗;保证强一致性;实现简单
- 缺点:线程需要等待,性能差;可能有死锁风险
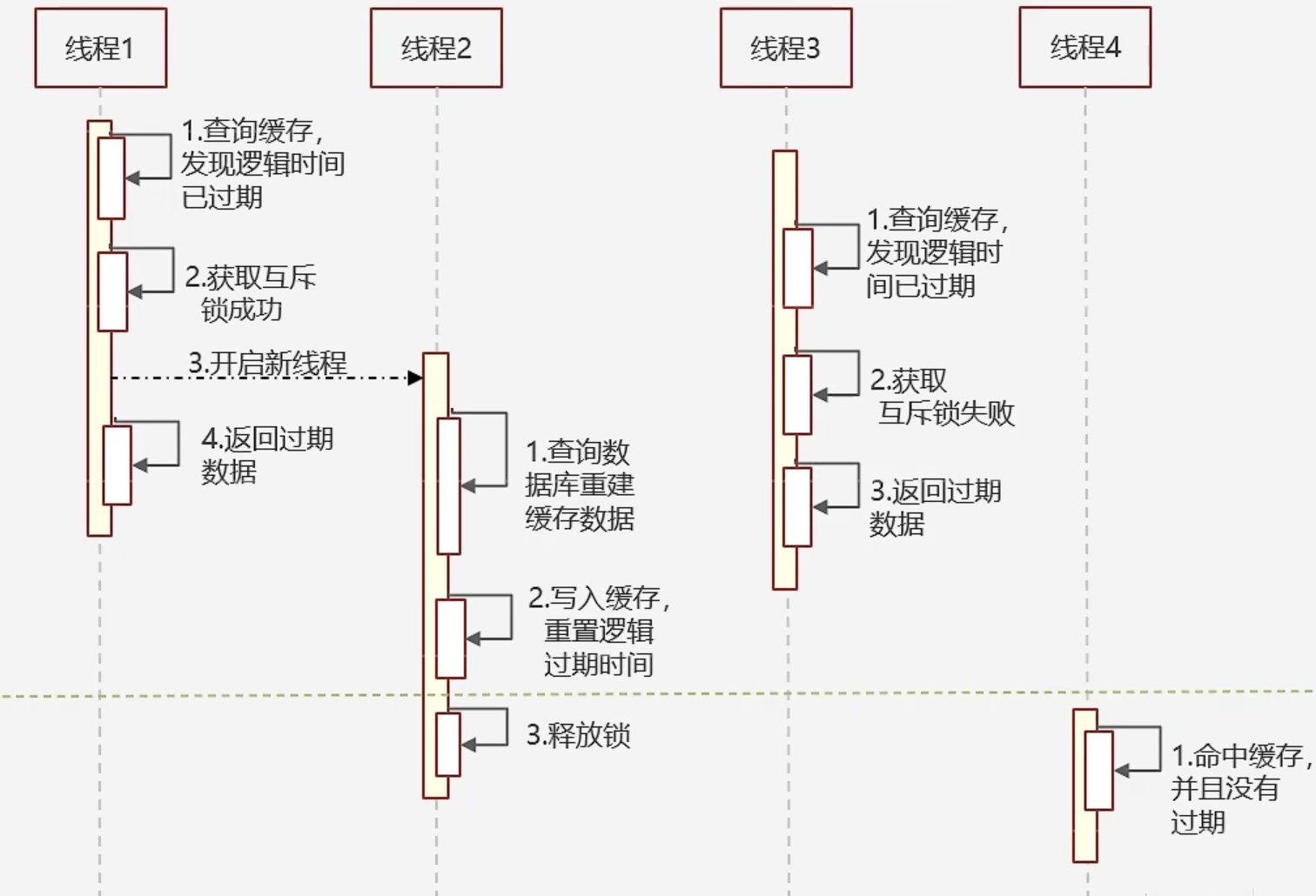
- 设置逻辑过期:① 在设置缓存键时,除了设置实际数据外,还设置一个过期时间字段,但不对当前键设置物理过期时间。② 查询时,从Redis中取出数据后,检查时间字段以判断数据是否过期。③ 如果数据已过期,则启动一个新的线程进行数据同步,而当前线程则正常返回旧数据,确保用户仍能获得响应,即使该数据不是最新的。【例】
{"id":"123","title":"Hyplus-OK","expire":153213455}- 优点:高可用性;性能优
- 缺点:不保证一致性;有额外内存消耗;实现复杂
4.3 缓存雪崩
缓存雪崩(Cache Avalanche):在设置缓存时,多个缓存key采用相同的过期时间,导致大量key同时过期失效,或Redis服务宕机,从而使得所有请求都转发至后端数据库。这种情况会导致数据库瞬间承受过大的压力,可能导致性能下降或崩溃。

解决方法:
- 给不同的key的TTL添加随机值
- 利用Redis集群提高服务的可用性:哨兵模式、集群模式
- 给缓存业务添加降级限流策略:Nginx或Spring Cloud Gateway
- 可作为系统的保底策略,适用于穿透、击穿、雪崩
- 给业务添加多级缓存:Guava或Caffeine
与缓存击穿的区别:缓存雪崩涉及多个缓存键的失效,而缓存击穿则是针对单个缓存键的失效情况。
4.4 双写一致性问题
双写问题:Redis作为缓存,MySQL的数据如何与Redis进行同步。双写一致性即为当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致。
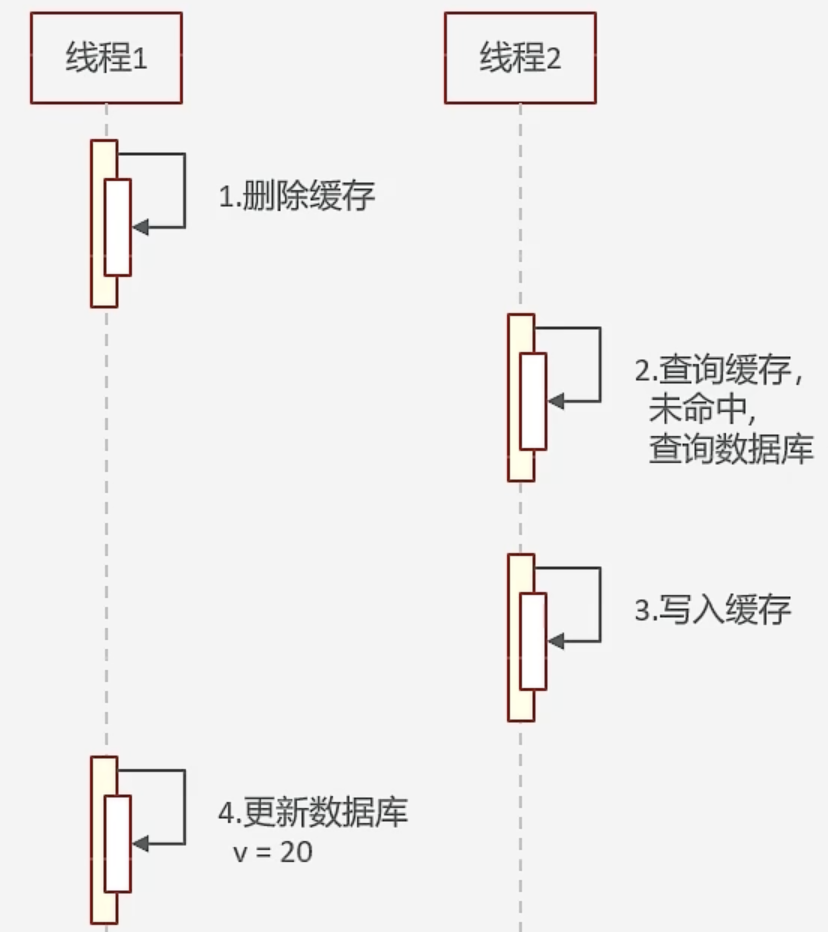
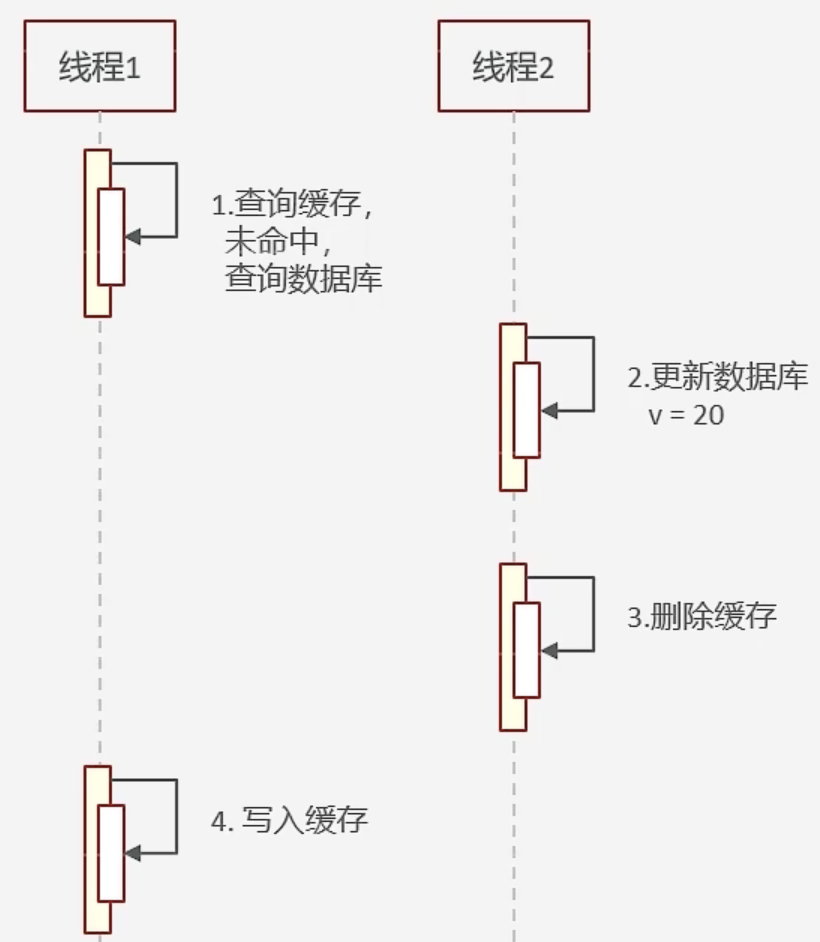
数据一致性问题:无论是先删缓存还是先修改数据库,都有可能导致最终双方的数据不一致。【例】设缓存与数据库中初始数据均为10,分别采用以下两种双写方案,均存在读脏数据的风险——
- 先删除缓存,再操作数据库
- 先操作数据库,再删除缓存
不追求强一致性的同步方案:
- 读操作:缓存命中,直接返回;缓存未命中查询数据库,写入缓存,设定超时时间
- 写操作——【延迟双删】(仍可能发生脏数据)
- 为何要删除两次缓存:尽量避免脏数据
- 为何要延时删除:采用主从数据库时,让主从有足够时间同步

强一致性的同步方案——采用Redisson读写锁(性能低):
- 共享锁(
readLock,读锁):加锁后其他可以共享读操作 - 排他锁(
writeLock,写锁):加锁后阻塞其他线程读写操作
仅保证最终一致性的异步方案——异步通知:
- 使用MQ进行缓存同步(需保证MQ的可靠性):更新数据后,通知缓存删除。

- 使用Canal组件实现数据同步:无需更改业务代码,只需部署一个Canal服务,其伪装成MySQL的从节点,通过读取MySQL的binlog数据更新缓存。(基于MySQL的主从同步来实现)
- MySQL的二进制日志(binlog)记录了所有的DDL(数据定义语言)和DML(数据操纵语言)语句,但不包括数据查询(
SELECT、SHOW)语句。
- MySQL的二进制日志(binlog)记录了所有的DDL(数据定义语言)和DML(数据操纵语言)语句,但不包括数据查询(

4.5 数据过期策略
Redis数据删除策略(数据过期策略)是指在Redis中为数据设置有效时间,当数据的有效时间到期后,系统会自动将其从内存中删除。在删除过程中,需要遵循特定的规则,这些规则被称为数据的删除策略。通过合理配置这些策略,Redis能够有效管理内存,确保系统性能和资源的高效利用。
在Redis中,数据的删除策略包括以下几种:
- 惰性删除:在为某个键设置过期时间后,系统不会主动删除该键。当访问该键时会检查其是否已过期,若已过期则将其删除,若未过期则返回该键的值。
- 优点:对CPU友好。只有在实际使用该键时才会进行过期检查,从而避免对未使用键的重复检查,节省了CPU资源。
- 缺点:对内存不友好。如果一个键已经过期但从未被访问,该键将继续占用内存。如果数据库中存在大量未使用的过期键,这些键将始终保留在内存中,导致内存无法释放。
【例】惰性删除如下例所示
set name kina 10 get name # 发现name过期了,直接删除key
- 定期删除:系统定期检查一定量的键是否过期,删除过期的键。具体方法是从一定数量的数据库中随机选取一定数量的键进行检查,并删除其中的过期键。
- 定期清理的两种模式:
- SLOW模式:定时任务,默认执行频率为10Hz,每次执行时间不超过25ms。可通过修改配置文件
redis.conf中的hz选项来调整执行频率。 - FAST模式:执行频率不固定,每次事件循环都会尝试执行,但两次执行之间的间隔不得低于2ms,每次执行时间不超过1ms。
- SLOW模式:定时任务,默认执行频率为10Hz,每次执行时间不超过25ms。可通过修改配置文件
- 优点:可以通过限制删除操作的执行时长和频率来减少对CPU的影响。此外,定期删除能够有效释放过期键占用的内存资源。
- 缺点:难以确定删除操作的执行时长和频率。如果执行过于频繁,定期删除策略可能与定时删除策略相似,从而对CPU造成负担;如果执行过于稀疏,则会导致过期键占用内存,类似于惰性删除的效果。此外,若在获取某个键时,该键的过期时间已到但尚未执行定期删除,系统仍可能返回该键的值,这将导致业务逻辑出现不可接受的错误。
- 定期清理的两种模式:
Redis的过期删除策略结合了惰性删除与定期删除两种策略,以优化内存管理和CPU使用效率。
4.6 数据淘汰策略
内存淘汰策略(数据淘汰策略):当Redis中的内存不足以存储新的键时,系统会根据特定规则删除现有数据,以腾出空间。
8种常见的数据淘汰策略:
- noeviction:不删除任何数据,内存不足直接报错。(默认策略)
- volatile-ttl:对于设置了TTL(Time-To-Live,过期时间)的key,比较剩余的TTL值,TTL越小越先被淘汰。
- volatile-Iru:对于设置了TTL的key,基于LRU算法进行淘汰。
- volatile-lfu:对于设置了TTL的key,基于LFU算法进行淘汰。
- volatile-random:对于设置了TTL的key,随机进行淘汰。
- allkeys-lru:对于全体key,基于LRU算法进行淘汰。
- allkeys-lfu:对于全体key,基于LFU算法进行淘汰。
- allkeys-random:对于全体key,随机进行淘汰。
两种算法:
- LRU(Least Recently Used):最少最近使用。用当前时间减去最后一次访问时间,值越大则淘汰优先级越高。【例】key1在3s之前访问,key2在9s之前访问,删除key2。
- LFU(Least Frequently Used):最少频率使用。统计每个key的访问频率,值越小淘汰优先级越高。【例】key1最近5s访问了4次,key2最近5s访问了9次, 删除key1。
配置文件redis.conf中常见的淘汰策略配置项:
maxmemory-policy noeviction:配置淘汰策略maxmemory ?mb:最大可使用内存,即占用物理内存的比例,默认值为e,表示不限制。生产环境中根据需求设定,通常设置在50%以上。maxmemory-samples count:设置redis需要检查key的个数
使用建议:
- 优先使用allkeys-lru:该策略充分利用LRU算法的优势,将最近最常访问的数据保留在缓存中。适用于业务中存在明显冷热数据区分的场景。
- 如果数据访问频率差别不大,没有明显的冷热数据区分,建议使用allkeys-random,随机选择淘汰。
- 针对有置顶需求的业务,可以采用volatile-lru策略,同时确保置顶数据不设置过期时间,这样这些数据将不会被删除,系统将优先淘汰其他设置了过期时间的数据。
- 对于短时高频访问的数据,建议使用allkeys-lfu或volatile-lfu策略,以便有效管理和淘汰不常用的数据。
- 数据库有1000万数据,Redis只能缓存20w数据,如何保证Redis中的数据都是热点数据?
- 使用allkeys-lru(挑选最近最少使用的数据淘汰)淘汰策略,留下来的都是经常访问的热点数据。
- Redis的内存用完了会发生什么?
- 主要看数据淘汰策略是什么?如果是默认配置,则直接报错。
5 Redis分布式锁
直接使用synchronized代码块的方式只适合于简单的单体项目,对于分布式集群应采用分布式锁,常见于定时任务、下单、缓存、秒杀、幂等性场景。
5.1 实现方式与有效时长控制
Redis底层实现分布式锁主要利用Redis的setnx命令(SET if not exists)。
# 获取锁:添加锁,其中NX表示互斥,EX用于设置超时时间
SET lock value NX EX 10
# 释放锁:删除即可
DEL key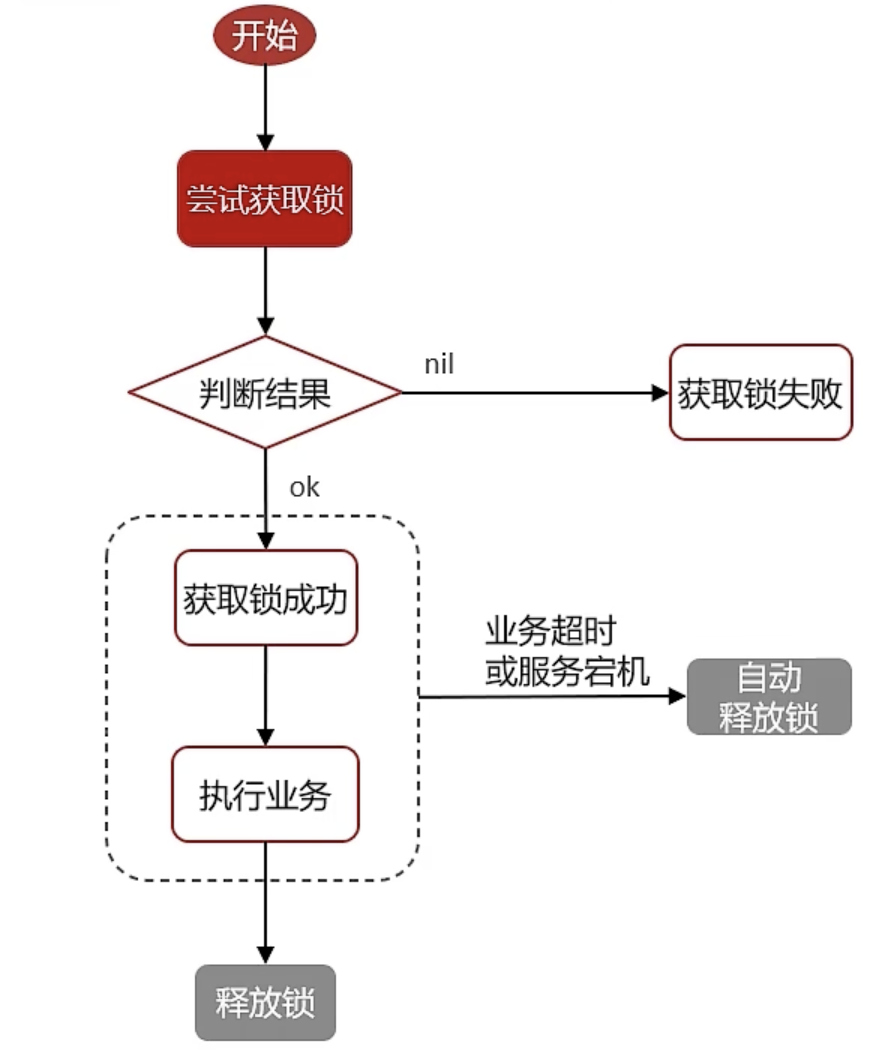
在Redis中实现分布式锁时,合理控制锁的有效时长是至关重要的。若有效时间设置过短,可能导致业务操作未完成时锁被自动释放,从而引发问题。
解决方案:
- 预估锁的有效时间:开发人员可以根据经验预估业务代码的执行时间,并将锁的有效期设置得比预估时间长,以确保不会因自动解锁而影响客户端的业务执行。
- 锁的续期机制:在成功加锁后,可以启动一个守护线程,默认有效期为用户设定的时间。该线程每隔一定时间(如10秒)就会将锁的有效期续期至用户设定的时间。只要持有锁的客户端未宕机,就能持续保持锁的有效性,直到业务代码执行完毕并由客户端自行解锁。如果客户端宕机,锁将在有效期结束后自动释放。
5.2 Redisson分布式锁
上述第二种解决方案可以利用Redis官方提供的Redisson库来实现锁的续期功能。执行流程原理如下,核心为WatchDog(看门狗),一个线程获取锁成功后,WatchDog会给持有锁的线程续期(默认为每10秒续期一次):

代码使用步骤如下:
pom.xml加入Redisson依赖(见前述布隆过滤器)- 定义配置类
@Configuration
public class RedisConfig {
@Bean
public RedissonClient redissonClient(){
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.200.130:6379") .setPassword("leadnews");
return Redisson.create(config);
}
}- 业务代码加入分布式锁,其中加锁、设置过期时间等底层操作均为基于lua脚本完成,以保证执行多条Redis命令时的原子性
public void redisLock() throws InterruptedException {
RLock lock = redissonClient.getLock("anyLock");
try {
// 第一个参数(30)表示尝试获取分布式锁,并且最大的等待获取锁的时间为30s
// 第二个参数(10)表示上锁之后,10s内操作完毕将自动释放锁(可选)
boolean isLock = lock.tryLock(30, 10, TimeUnit.SECONDS);
String num = redisTemplate.opsForValue().get("num");
Integer intNum = Integer.parseInt(num);
if (intNum == null || intNum <= 0) {
throw new RuntimeException("商品已抢完");
}
if (isLock) {
intNum = intNum - 1;
redisTemplate.opsForValue().set("num", intNum.toString());
System.out.println(redisTemplate.opsForValue().get("num"));
}
} finally {
// 释放锁
lock.unlock();
}
}- Jmeter测试

Redisson分布式锁的特性:
- 可重入:原理为利用Hash结构记录锁对应的线程ID和重入次数。
public void add1() {
RLock lock = redissonClient.getLock("hypluslock");
boolean isLock = lock.tryLock(30, 10, TimeUnit.SECONDS);
// 执行业务...
add2();
// 释放锁
lock.unlock();
}
public void add2() {
RLock lock = redissonClient.getLock("hypluslock");
boolean isLock = lock.tryLock(30, 10, TimeUnit.SECONDS);
// 执行业务...
// 释放锁
lock.unlock();
}- 主从一致性——RedLock(红锁):不只在一个Redis实例上创建锁,应在
n个Redis实例上创建n / 2 + 1把锁,避免了在一个Redis实例上加锁。以下两图分别为发生脑裂时读脏数据的情形与使用红锁的解决方案。- 缺点:实现复杂;性能差;运维繁琐(Redis官方不建议使用红锁)
- 保证主从强一致性的解决方案:不使用AP思想的Redis,改用CP思想的Zookeeper


6 Redis事务
Redis的事务与传统事务有所不同。传统的ACID事务是一个原子操作,意味着事务中的所有命令要么全部执行,要么全部不执行。
在Redis中,事务的本质是一组命令的集合。Redis事务支持一次执行多个命令,并且所有命令都会被序列化。在事务执行过程中,命令按照顺序串行化执行,其他客户端的命令请求不会插入到当前事务的执行序列中。
Redis事务的特点是一次性、顺序性和排他性地执行队列中的一系列命令。在Redis中,单条命令是原子性执行的,但事务本身并不保证原子性,并且不支持回滚。
事务相关的命令:
MULTI:组装事务EXEC:执行事务DISCARD:取消事务WATCH:监视key,一旦这些key在事务执行之前被改变,则取消事务的执行UNWATCH:取消WATCH命令对所有key的监视

7 网络模型
Redis是单线程的,但依旧很快,原因如下:
- 完全基于内存;用C语言编写。
- 单线程拉烟避免不必要的上下文切换可竞争条件。
- 数据简单,数据操作也相对简单
- 使用多路I/O复用模型,非阻塞I/O
bgsave在后台执行RDB的保存,不影响主线程的正常使用,不会产生阻塞。bgrewriteaof在后台执行AOF文件的保存,不影响主线程的正常使用,不会产生阻塞。
Redis是纯内存操作,执行速度非常快,其性能瓶颈为网络延迟而非执行速度,I/O多路复用模型主要即实现了高效的网络请求。
7.1 用户空间与内核空间
Linux系统中一个进程使用的内存情况划分两部分:
- 用户空间(User Space):只能执行受限的命令(Ring3),并且不能直接调用系统资源,必须通过内核提供的接口来访问
- 内核空间(Kernel Space):可以执行特权命令(Ring0),调用一切系统资源

Linux系统为了提高I/O效率,会在用户空间和内核空间都加入缓冲区:
- 写数据时,将用户缓冲数据拷贝到内核缓冲区,然后写入设备
- 读数据时,从设备读取数据到内核缓冲区,然后拷贝到用户缓冲区
7.2 阻塞I/O
阻塞I/O即两个阶段都必须阻塞等待:
- 阶段一:
- 用户进程尝试读取数据(例如网卡数据)
- 此时数据尚未到达,内核需要等待数据
- 此时用户进程也处于阻塞状态
- 阶段二:
- 数据到达并拷贝到内核缓冲区,代表已就绪
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷口完成,用户进程解除阻塞,处理数据

可见在阻塞IO模型中,用户进程在两个阶段均为阻塞状态。
7.3 非阻塞I/O
非阻塞I/O的recvfrom操作会立即返回结果而非阻塞用户进程。
- 阶段一:
- 用户进程尝试读取数据(比如网卡数据)
- 此时数据尚未到达,内核需要等待数据
- 返回异常给用户进程
- 用户进程拿到error后,再次尝试读取
- 循环往复,直至数据就绪
- 阶段二:
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程解除阻塞,处理数据

可见在非阻塞IO模型中,用户进程在第一个阶段是非阻塞,第二个阶段是阻塞状态。虽然是非阻塞,但性能并没有得到提高。而且忙等机制会导致CPU空转,CPU使用率暴增。
7.4 I/O多路复用
I/O多路复用利用单个线程来同时监听多个Socket,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
- 阶段一:
- 用户进程调用
select,指定要监听的Socket集合 - 内核监听对应的多个Socket
- 任意一个或多个Socket数据就绪则返回
readable - 此过程中用户进程阻塞
- 用户进程调用
- 阶段二:
- 用户进程找到就绪的Socket
- 依次调用
recvfrom读取数据 - 内核将数据拷贝到用户空间
- 用户进程处理数据

监听Socket的方式、通知的方式有多种实现,常见的有select(如上图所用)、poll、epoll,其差异如下:
select和poll只会通知用户进程有Socket就绪,但
不确定具体是哪个Socket,需要用户进程逐个遍
历Socket来确认。epoll则会在通知用户进程Socket就绪的同时,把
已就绪的Socket写入用户空间。
7.5 Redis网络模型
Redis通过I/O多路复用来提高网络性能,并且支持各种不同的多路复用实现,并且将这些实现进行封装,提供了统一的高性能事件库(I/O多路复用+事件派发)。

《Redis原理篇:持久化、主从与集群、缓存问题、分布式锁…》有1条评论