深度学习笔记——大语言模型(LLM)基础:注意力机制、Transformer。持续更新!
1 注意力机制
【例】动物需要在复杂环境下有效关注值得注意的点
心理学框架:人类根据随意线索和不随意线索选择注意点
1.1 基本概念
卷积、全连接、池化层都只考虑不随意线索。注意力机制(Attention Mechanism)则显示地考虑随意线索/意志线索(Volitional Cue),常称为查询(Query)。每个输入是一个值(Value)和不随意线索/键(Key)的对(x_i,y_i)。
通过注意力池化层(Attention Pooling)来对查询 x有偏向性地选择输入f(x),可以表示为
\begin{aligned}
f(x)=\sum\limits_i \alpha(x,x_i)y_i
\end{aligned}其中\alpha(x,x_i)为注意力权重。
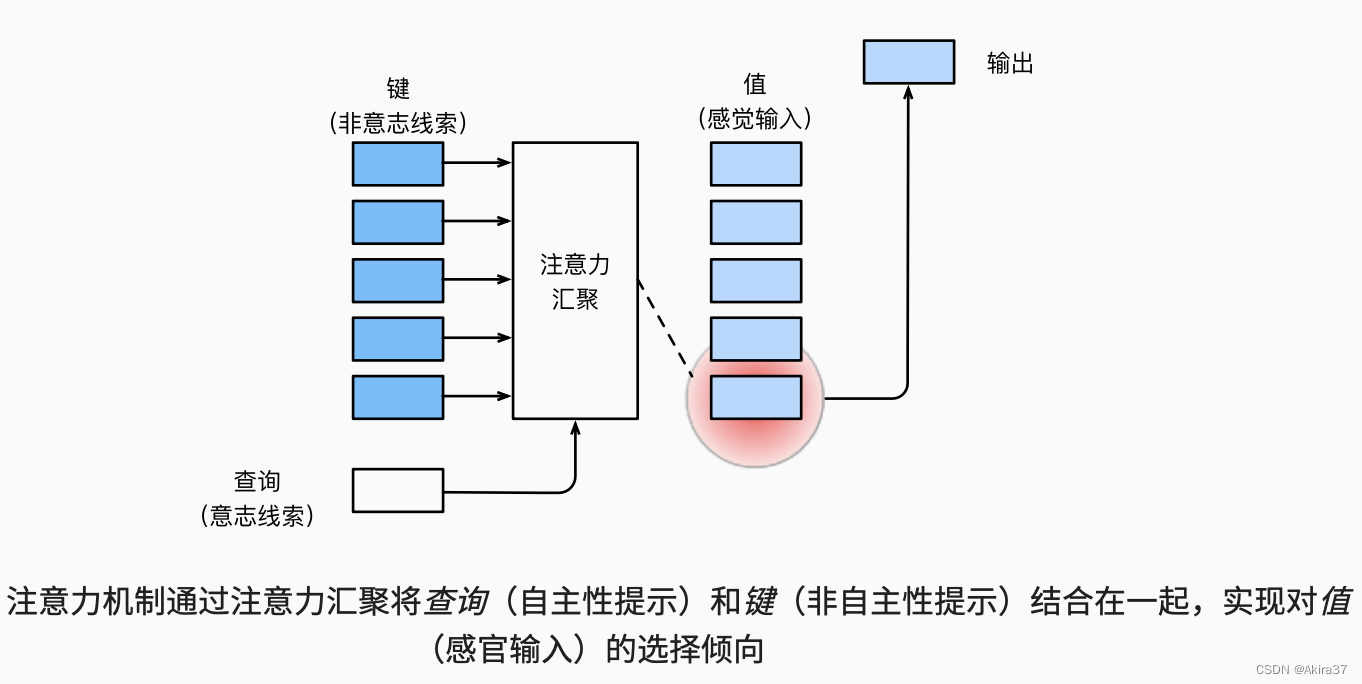
1.2 非参数注意力池化
给定询问x以及键值对数据(x_i,y_i),\ i=1,2,\cdots,n。平均池化(Average Pooling)是前文解决回归问题时常用的最简单的估计器,即
\begin{aligned}
f(x)=\frac1n\sum\limits_{i=1}^n y_i
\end{aligned}更好的方案是60年代提出的Nadaraya-Watson核回归(Nadaraya-Watson Kernel Regression),如下所示
\begin{aligned}
f(x)=\sum\limits_{i=1}^n \frac{K(x-x_i)}{\sum\limits_{j=1}^n K(x-x_j)}y_i
\end{aligned}其中K(u)为高斯核(Gaussian kernel),定义为
\begin{aligned}
K(u)=\frac1{\sqrt{2\pi}}\exp\left(-\frac{u^2}{2}\right)
\end{aligned}则非参数的Nadaraya-Watson核回归可化简为
\begin{aligned}
f(x) &=\sum\limits_{i=1}^n \frac{\exp \left(-\frac12(x-x_i)^2\right)}{\sum\limits_{j=1}^n \exp\left(-\frac12(x-x_j)^2\right)}y_i\\
&=\sum\limits_{i=1}^n \text{softmax}\left(-\frac12(x-x_i)^2\right)y_i
\end{aligned}1.3 带参数注意力池化
非参数的Nadaraya-Watson核回归具有一致性(Consistency)的优点: 如果有足够的数据,此模型会收敛到最优结果。在此基础上引入可以学习的w,如下所示
\begin{aligned}
f(x)=\sum\limits_{i=1}^n \text{softmax}\left(-\frac12\left((x-x_i)w\right)^2\right)y_i
\end{aligned}2 注意力评分函数
上述高斯核指数部分可以视为注意力评分函数(Attention Scoring Function),简称评分函数,是询问和键的相似度。注意力权重是分数的softmax结果。
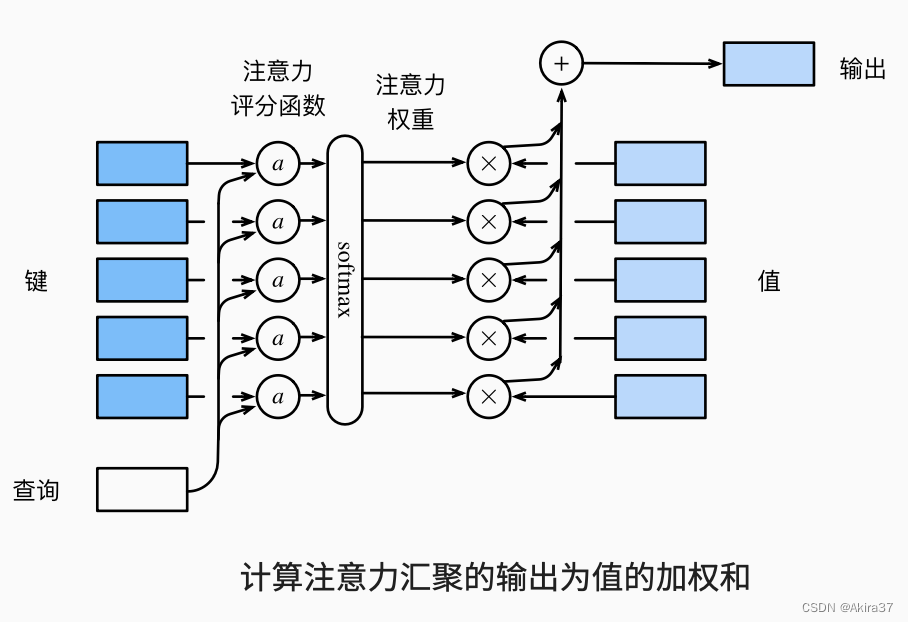
2.1 高维度注意力池化
设询问\mathbf{q} \in \mathbb{R}^q,键值对(\mathbf{k}_1,\mathbf{v}_1),\cdots,(\mathbf{k}_m,\mathbf{v}_m),其中\mathbf{k}_i\in \mathbb{R}^k,\mathbf{v}_i\in \mathbb{R}^v,则注意力池化函数f表示为
\begin{aligned}
f(\mathbf{q},(\mathbf{k}_1,\mathbf{v}_1),\cdots,(\mathbf{k}_m,\mathbf{v}_m)) &=\sum\limits_{i=1}^m \alpha(\mathbf{q},\mathbf{k}_i)\mathbf{v}_i \in \mathbb{R}^v \\
\alpha(\mathbf{q},\mathbf{k}_i)=\text{softmax}(a(\mathbf{q},\mathbf{k}_i)) &=\frac{\exp(a(\mathbf{q},\mathbf{k}_i))}{\sum\limits_{j=1}^{m}\exp(a(\mathbf{q},\mathbf{k}_j))} \in \mathbb{R}
\end{aligned}其中a(\mathbf{q},\mathbf{k}_i)为评分函数。
2.2 加性注意力
当询问和键是不同长度的矢量时,可以使用加性注意力(Additive Attention)作为评分函数。设询问\mathbf{q} \in \mathbb{R}^q和键\mathbf{k}_i\in \mathbb{R}^k,可学习的参数为\mathbf{w}_v\in \mathbb{R}^h,\mathbf{W}_k \in \mathbb{R}^{h\times k},\mathbf{W}_q \in \mathbb{R}^{h\times q},则加性注意力的评分函数为
\begin{aligned}
a(\mathbf{q},\mathbf{k}_i)=\mathbf{w}_v^\text{T}\tanh(\mathbf{W}_q\mathbf{q}+\mathbf{W}_k\mathbf{k}_i) \in \mathbb{R}
\end{aligned}等价于将键与值合并放入一个隐藏大小为h、输出大小为1的单隐藏层MLP。
2.3 缩放点积注意力
若询问和键都是同样的长度d,则可使用缩放点积注意力(Scaled Dot-product Attention)。设\mathbf{q},\mathbf{k}_i \in \mathbb{R}^d,则评分函数为
\begin{aligned}
a(\mathbf{q},\mathbf{k}_i)=\frac{\left \langle \mathbf{q},\mathbf{k}_i \right \rangle }{\sqrt{d}}
\end{aligned}通常从小批量的角度来考虑提高效率:设有n个查询和m个键值对,其中查询和键的长度为d,值的长度为v,则查询\mathbf{Q}\in \mathbb{R}^{n\times d}、键\mathbf{K}\in \mathbb{R}^{m\times d}和值\mathbf{V}\in \mathbb{R}^{m\times v}的缩放点积注意力f为
\begin{aligned}
f(\mathbf{Q},\mathbf{K},\mathbf{V}) &=\text{softmax}(a(\mathbf{Q},\mathbf{K}))\mathbf{V} \in \mathbb{R}^{n\times v} \\
a(\mathbf{Q},\mathbf{K}) &=\frac{\mathbf{Q}\mathbf{K}^\text{T}}{\sqrt{d}} \in \mathbb{R}^{n\times m}
\end{aligned}可见此处直接将询问和键作内积。
3 自注意力
当查询、键和值来自同一组输入时称为自注意力(Self-attention)或内部注意力(Intra-attention)。
3.1 基本概念
给定序列\mathbf{x}_1,\cdots,\mathbf{x}_n,\forall \mathbf{x}_i \in \mathbb{R}^d,自注意力池化层将\mathbf{x}_i当做键、值、询问来对序列抽取特征得到\mathbf{y}_1,\cdots,\mathbf{y}_n,其中
\begin{aligned}
\mathbf{y}_i=f(\mathbf{x}_i,(\mathbf{x}_1,\mathbf{x}_1),\dots,(\mathbf{x}_n,\mathbf{x}_n)) \in \mathbb{R}^d
\end{aligned}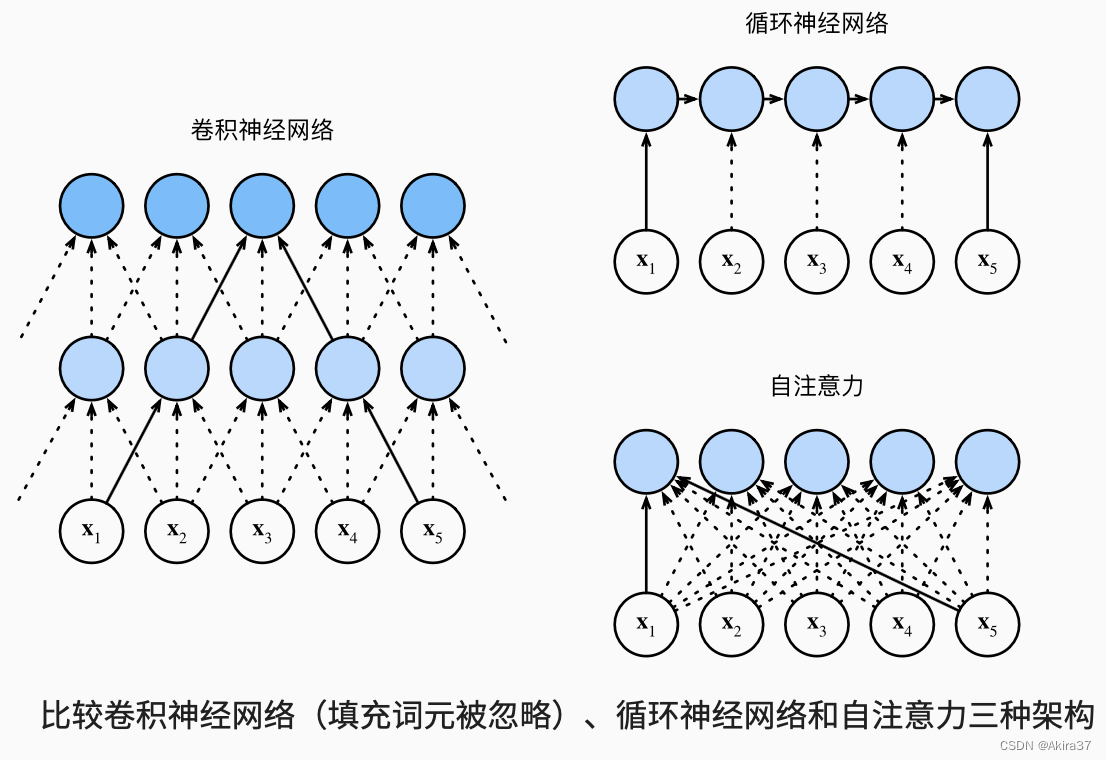
自注意力完全并行,最长序列为1,但对长序列计算复杂度高
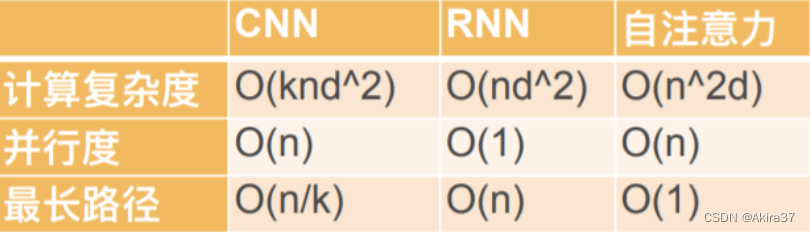
3.2 位置编码
跟CNN/RNN不同,自注意力并没有记录位置信息。
位置编码(Positional Encoding)在输入表示中加入位置信息,使得自注意力能够记忆位置信息。
设输入\mathbf{X}\in\mathbb{R}^{n\times d}为长度n的序列,则使用位置编码矩阵\mathbf{P}\in\mathbb{R}^{n\times d}来输出\mathbf{X}+\mathbf{P}作为自编码输入,其中\mathbf{P}的元素如下计算
\begin{aligned}
p_{i,2j} &=\sin\left(\frac{i}{10000^{\frac{2j}{d}}}\right)\\
p_{i,2j+1} &=\cos\left(\frac{i}{10000^{\frac{2j}d}}\right)
\end{aligned}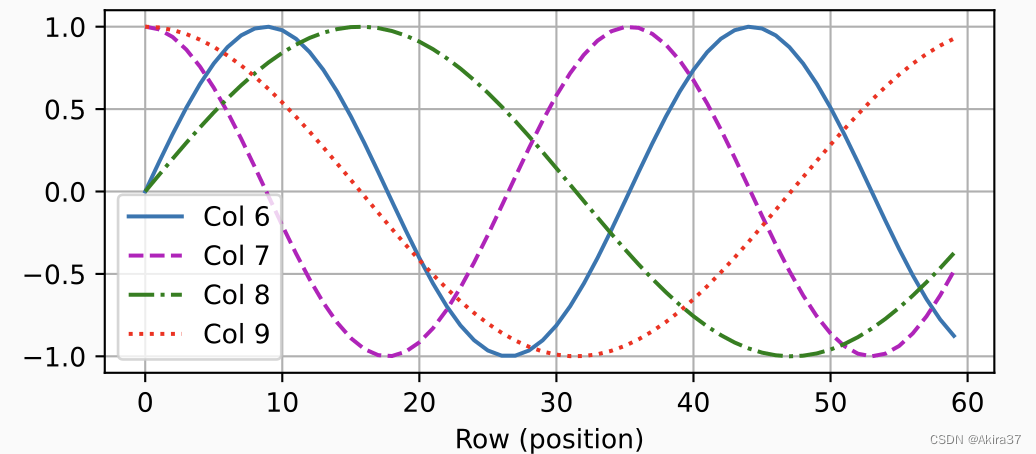
3.3 绝对、相对位置信息
观察下图中的二进制编码可知,每个数字、每两个数字和每四个数字上的比特值在第一个最低位、第二个最低位和第三个最低位上分别交替。
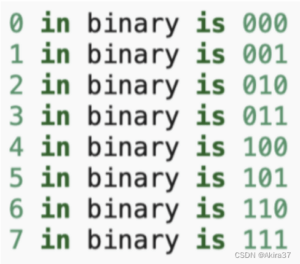
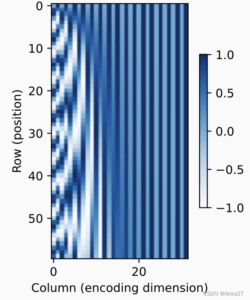
在二进制表示中,较高比特位的交替频率低于较低比特位, 与下面的热图所示相似,只是位置编码通过使用三角函数在编码维度上降低频率。 由于输出是浮点数,因此此类连续表示比二进制表示法更节省空间。
对于任何确定的位置偏移\delta,位置i+\delta处的位置编码可以线性投影位置i处的位置编码来表示。令\omega_i=\frac{1}{10000^{\frac{2j}{d}}},则
\begin{aligned}
\begin{bmatrix}
\cos(\delta \omega_j) & \sin(\delta\omega_j) \\
-\sin(\delta \omega_j) & \cos(\delta \omega_j)
\end{bmatrix}\begin{bmatrix}
p_{i,2j} \\
p_{i,2j+1}
\end{bmatrix}=\begin{bmatrix}
p_{i+\delta,2j} \\
p_{i+\delta,2j+1}
\end{bmatrix}
\end{aligned}易知左边的投影矩阵与i无关。
4 Transformer
Transformer模型完全基于注意力机制,没有任何卷积层或循环神经网络层,基于编码器-解码器架构来处理序列对。
4.1 总体架构
Transformer的编码器和解码器是基于自注意力的模块叠加而成的,源(输入)序列和目标(输出)序列的嵌入(Embedding)表示将加上位置编码,再分别输入到编码器和解码器中。
所有子层之间使用残差链接。
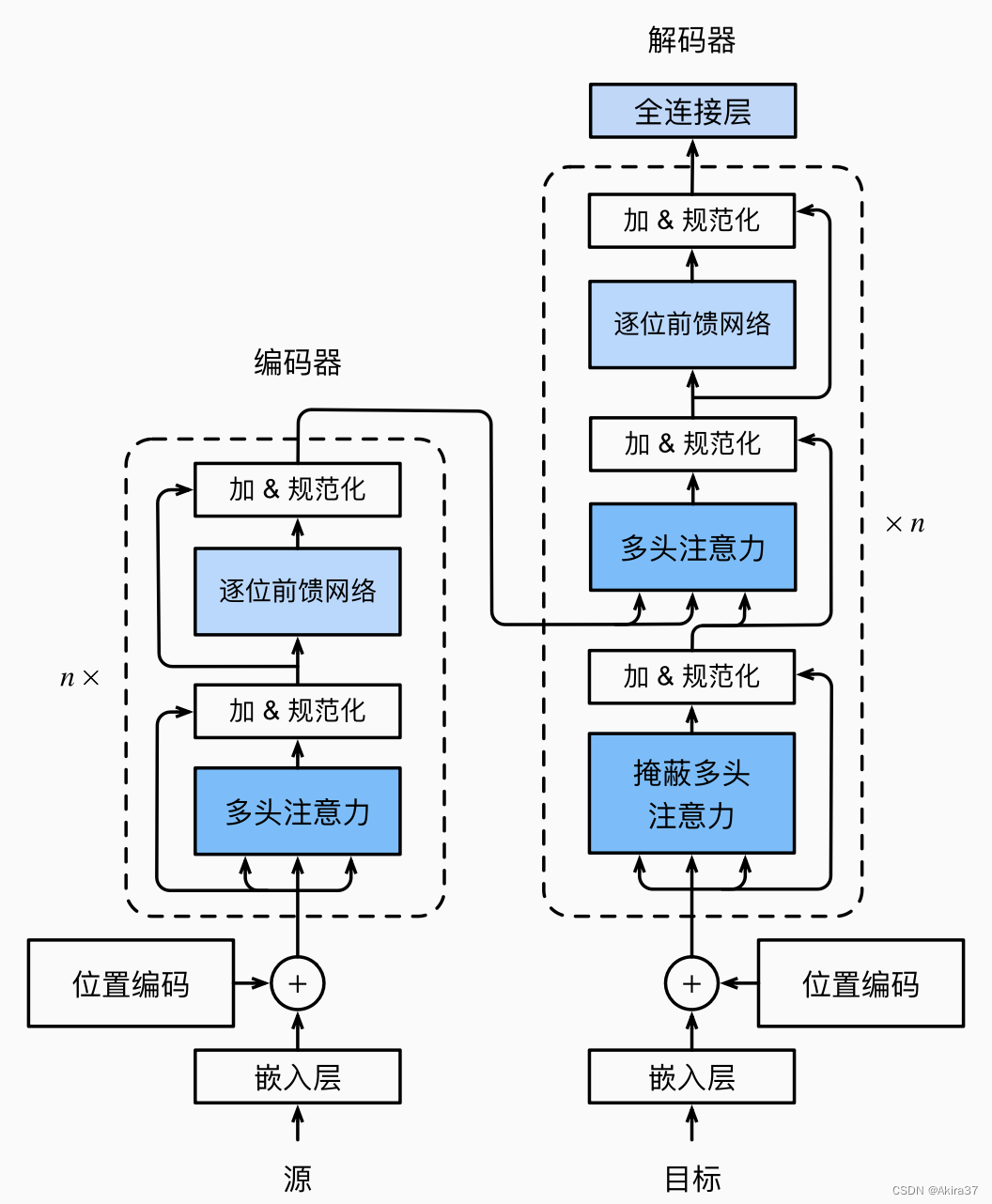
4.2 多头自注意力
多头自注意力(Multi-head Self-attention)对同一键、值、询问,希望抽取不同的信息,例如短距离关系和长距离关系。使用h个独立的注意力池化,合并各个头(Head)的输出得到最终输出。
设询问\mathbf{q}\in \mathbb{R}^{d_q},键\mathbf{k}\in \mathbb{R}^{d_k},值\mathbf{v}\in \mathbb{R}^{d_v},头i的可学习参数\mathbf{W}_i^{(q)}\in \mathbb{R}^{p_q\times d_q},\mathbf{W}_i^{(k)}\in \mathbb{R}^{p_k\times d_k},\mathbf{W}_i^{(v)}\in \mathbb{R}^{p_v\times d_v},则头i的输出为
\begin{aligned}
\mathbf{h}_i=f(\mathbf{W}_i^{(q)}\mathbf{q},\mathbf{W}_i^{(k)}\mathbf{k},\mathbf{W}_i^{(v)}\mathbf{v}) \in \mathbb{R}^{p_v}
\end{aligned}输出的可学习参数\mathbf{W}_o\in\mathbb{R}^{p_o\times hp_v},则多头注意力的输出为
\begin{aligned}
\mathbf{W}_o\begin{bmatrix}
\mathbf{h}_1 \\
\vdots \\
\mathbf{h}_h
\end{bmatrix} \in \mathbb{R}^{p_o}
\end{aligned}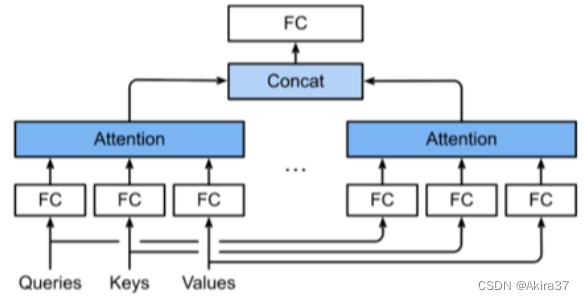
有掩码的多头注意力:解码器对序列中一个元素输出时,不应该考虑该元素之后的元素,因此可通过掩码来实现。即计算\mathbf{x}_i输出时,假装当前序列长度为i。
4.3 基于位置的前馈网络
基于位置的前馈网络(Positionwise Feed-forward Network)将输入形状由(b,n,d)变换成(bn,d),输出形状由(bn,d)变化回(b,n,d)。等价于两层1\times 1卷积层,即全连接层。
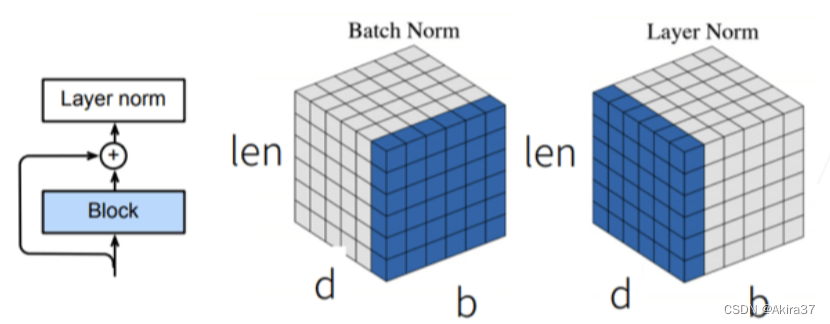
4.4 层规范化
批量规范化(详见CNN 2.5)对每个特征/通道(列)里元素进行归一化,不适合序列长度会变的NLP应用。
层规范化(Layer Normalization)对每个样本(行)里的元素进行归一化。
4.5 信息传递与输出预测
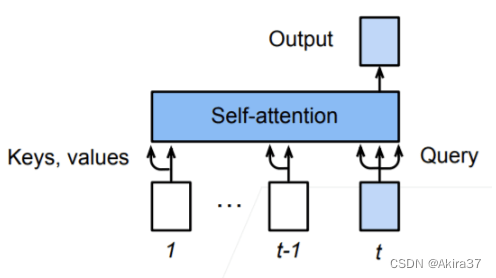
编码器到解码器的信息传递:编码器中的输出\mathbf{y}_1,\cdots,\mathbf{y}_n作为解码中第i个Transformer块中多头注意力的键和值,其询问来自目标序列。这意味着编码器和解码器中块的个数和输出维度都是一样的。
预测:预测第t+1个输出时,解码器中输入前t个预测值,在自注意力中作为键和值,其第t个还同时作为询问。
5 大语言模型
相关阅读:Spring AI大模型应用开发教程
大语言模型(Large Language Model,LLM,简称大模型)是指基于Transformer架构,通过大规模参数规模、海量文本预训练和高效微调策略,具备了理解、生成、推理等强大的自然语言处理能力,能够捕捉语言的深层语义、语法规则和世界知识,并可通过微调适配多种自然语言处理任务的生成式语言模型。限于篇幅,本章仅介绍部分核心理论知识,实际应用请参阅其他博文。
与传统语言模型(如RNN-based模型、小规模Transformer模型)相比,LLM具有以下核心特征:
- 参数规模庞大:参数数量是LLM的重要标志之一,从早期的数十亿(如GPT-2的15亿参数)到后来的万亿级别(如GPT-5、PaLM 2等),大规模参数为模型捕捉复杂语言模式和知识提供了基础。
- 预训练-微调范式:采用“预训练+微调”的两阶段学习模式,预训练阶段学习通用语言知识和世界常识,微调阶段针对具体任务适配,大幅降低了特定任务的训练成本。
- 涌现能力(Emergent Abilities):当模型参数规模达到一定阈值后,会涌现出小规模模型不具备的能力,如逻辑推理、多轮对话、跨任务迁移等,这是LLM区别于传统模型的关键特性。
- 生成能力突出:GPT系列等LLM具备强大的文本生成能力,能够生成流畅、连贯、符合语境的自然语言文本,涵盖故事创作、代码编写、报告撰写等多种场景。
5.1 核心技术范式
LLM的成功离不开各类技术范式的支撑,其中预训练-微调是基础框架,而提示学习(Prompt Learning)则是适配小规模数据场景的重要优化方向。
5.1.1 预训练阶段
预训练(Pretrain)是LLM构建通用语言能力的核心阶段,目的是让模型从海量无标注文本中学习语言的内在规律和世界知识。该阶段的核心是设计合理的预训练任务,常见任务包括:
- 自回归语言建模(Autoregressive Language Modeling,AR):GPT系列LLM所采用的核心预训练任务。任务目标为给定前文文本,预测下一个token(字/词/子词)的概率。通过该任务,模型能够学习文本的序列依赖关系和生成逻辑。如下表达式所示,其中
\mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_n为长度为n的输入文本序列(token嵌入维度为d),\theta为模型参数:
\begin{aligned}
L_{\text{AR}}=-\sum\limits_{i=1}^n \log P(\mathbf{x}_i\mid \mathbf{x}_1,\mathbf{x}_2,\dots,\mathbf{x}_{i-1};\theta)
\end{aligned}- 掩码语言建模(Masked Language Modeling, MLM):常见于BERT系列等双向编码模型,任务目标为随机掩码输入文本中的部分token,让模型根据上下文预测被掩码的token。该任务能让模型学习文本的双向语义依赖,如下表达式所示,其中
\mathbf{x}_{\setminus i} \in \mathbb{R}^{(n-1)\times d}表示去除第i个掩码token后的剩余文本:
\begin{aligned}
L_{\text{MLM}}=-\sum\limits_{i\in \text{masked}} \log P(\mathbf{x}_i\mid \mathbf{x}_{\setminus i};\theta)
\end{aligned}- 其他辅助任务:部分模型训练时还会进行句子排序、Next Sentence Prediction(NSP)、文档级语义建模等任务来增强模型的语言理解能力,学习更长文本的语义关联。
预训练数据的质量和规模直接影响LLM的性能,通常采用通用领域的海量文本数据(如网页文本、书籍、论文、新闻等),数据量可达万亿token级别,确保模型能够学习到广泛的语言知识和世界常识。
5.1.2 微调
预训练后的LLM具备了通用语言能力,但要适配具体任务(如情感分析、机器翻译、问答系统等),还需进行微调(Fine-Tuning)。
核心思路:基于预训练模型的参数,使用少量标注的特定任务数据进行二次训练,让模型调整参数以适配任务需求。
常见的微调策略可分为以下两大类:
- 全参数微调:对预训练模型的所有参数进行调整,适配效果最好,但计算成本高,需要大量计算资源。
- 参数高效微调(Parameter-Efficient Fine-Tuning,PEFT):仅调整模型的部分参数,例如在Transformer层插入适配器(Adapter)、微调注意力层参数等,在保证适配效果的同时,大幅降低计算成本,适合资源有限的场景,如LoRA、Prefix Tuning等方法。
5.1.3 提示学习
当特定任务的标注数据极少(少样本)或没有(零样本)时,传统微调方法效果较差。提示学习(Prompt Learning)通过将具体任务转化为自然语言提示词(Prompt,指令)的形式,引导LLM直接利用预训练阶段习得的知识完成任务,无需大量标注数据。
核心思想:将任务描述和少量示例(少样本)或无示例(零样本)以自然语言的方式输入模型,让模型根据提示直接生成任务结果。
【例】情感分析任务可设计提示:文本:“这部电影非常精彩”,情感:正面/负面?答案:,模型会根据提示生成正面的结果。
提示学习的关键是提示词工程(Prompt Engineering,指令工程),即设计合理的提示模板,让模型能够准确理解任务需求。随着技术发展,自动提示生成(Auto-Prompt)、提示词优化等方法也逐渐成熟,进一步提升了提示学习的效果。
5.2 典型大模型简介
自2018年Transformer提出后,大语言模型迅速发展,涌现出多个具有里程碑意义的模型。本节介绍目前最常用的典型LLM。
闭源模型:
- GPT(Generative Pre-trained Transformer)系列(OpenAI):基于Transformer解码器架构,采用自回归语言建模预训练任务。
- GPT-1(2018):首个基于Transformer的预训练语言模型,参数规模1.17亿,验证了“预训练-微调”范式在NLP任务中的有效性。
- GPT-2(2019):参数规模提升至15亿,首次展现了模型的零样本迁移能力,无需微调即可完成部分NLP任务。
- GPT-3(2020):参数规模达到1750亿,是首个真正意义上的“大语言模型”,涌现出强大的逻辑推理、多轮对话能力,支持零样本、少样本学习,推动了提示学习的发展。
- GPT-4(2023):多模态大语言模型,支持文本和图像输入,参数规模未公开(推测万亿级别),在复杂推理、专业领域(如法律、医学、代码编写)的能力大幅提升,具备更强的安全性和对齐能力。
- GPT-5及更先进模型:持续发展中
- BERT(Bidirectional Encoder Representations from Transformers)系列(Google):基于Transformer编码器架构,采用掩码语言建模和Next Sentence Prediction(NSP)作为预训练任务,主要聚焦于语言理解任务。
- BERT-base:参数规模110M(另有BERT-large参数规模340M),在多个语言理解任务(情感分析、问答、命名实体识别等)上刷新了当时的SOTA结果。
- RoBERTa、ALBERT等后续衍生模型通过优化预训练策略(如增大batch size、移除NSP任务、参数共享等),进一步提升了模型性能和训练效率。
- Claude系列(Anthropic):基于Transformer解码器架构,核心特色是“安全对齐”和超长上下文窗口。例如早期的Claude 3 Opus支持100万token的上下文,能完整处理一本长篇书籍或海量文档;通过强化学习与人类反馈(RLHF)技术,大幅降低了恶意内容生成风险,在法律文档分析、企业级对话系统等对安全性要求高的场景中极具优势。现今的Claude系列模型在编码能力上亦十分优异。
- Gemini系列(Google):基于Transformer的混合架构(融合编码器-解码器优势),支持文本、图像、音频、视频、代码的理解与生成。其核心创新是“跨模态统一建模”,能实现文本生成图像、视频内容摘要、多模态逻辑推理(如根据图像内容撰写代码)等复杂任务,参数规模推测为万亿级别,定位是对标GPT系列的全能型模型。
- PaLM 2(Google):于2023年发布,是PaLM(Pretraining and Language Model)的升级版,基于Transformer解码器架构,参数规模虽小于GPT系列,但通过优化预训练数据(多语言文本、代码、数学公式)和模型结构,在数学推理、代码生成和多语言处理上性能优异。支持100多种语言,且推出了不同规模版本(Gecko、Otter、Bison、Unicorn),可适配从手机端到云端的不同部署场景。
开源模型:
- LLaMA系列(Meta):基于Transformer解码器架构,参数规模从7B到65B不等,开源后被广泛用于微调适配特定场景(如医疗、教育、代码生成),衍生出多个优化版本(如Alpaca、Vicuna等)。
- Falcon(Technology Innovation Institute,TII):基于Transformer解码器架构,参数规模有7B、40B等版本。其核心优势是训练效率高,采用了优化的预训练策略和并行计算框架,同时在商业使用上限制较少(允许非商业和商业应用)。Falcon-40B在通用文本生成、逻辑推理任务上性能接近LLaMA系列,是开源社区微调适配垂直领域的热门选择。
- Mistral(Mistral AI):采用分组注意力机制(Grouped-Query Attention)优化推理效率,参数规模7B/13B,在性能和效率上取得了较好的平衡。
- Deepseek(深度求索):国产开源大语言模型的代表,涵盖通用版(Deepseek-LLM)和专业版(Deepseek-Coder、Deepseek-Math等)。其中Deepseek-Coder是代码生成领域的佼佼者,支持Python、Java等多种编程语言,能实现代码生成、调试、注释撰写,其核心是预训练阶段融入了海量代码数据,在编程任务上的性能超越多个同类开源模型。
- 通义千问(Qwen,阿里达摩院):基于Transformer改进架构,参数规模从7B到175B或更多不等。优势是中文语义理解精准,支持多模态任务(文本生成、图像理解),开源版本可自由微调适配电商、金融等垂直领域,同时具备高效推理性能,可部署于云端和边缘设备。
- 盘古大模型(华为):分为通用大模型和行业大模型(医疗、金融、气象等),基于Transformer编码器-解码器架构,融入知识增强技术。在行业应用中表现突出,例如盘古医疗能精准分析病历文本、辅助肿瘤特征识别;盘古气象大模型通过融合气象数据,提升了短期天气预报的准确性。
- ERNIE(百度):基于Transformer架构,通过引入知识掩码策略(如实体掩码、短语掩码),增强了模型对中文语义和知识的理解能力。
5.3 主要应用场景
LLM凭借强大的语言能力,已广泛应用于多个领域,涵盖文本生成、语言理解、人机交互等多个方向:
- 文本生成:包括文案撰写、新闻报道、故事创作、代码生成、学术论文辅助写作等。例如,GPT-5、Gemini等模型可生成符合语法规范的Python、Java等代码,并能根据需求优化代码逻辑。
- 语言理解与分析:情感分析、文本分类、命名实体识别、文本摘要、信息抽取等。例如,利用LLM对用户评论进行情感倾向判断,辅助企业了解用户需求。
- 人机对话系统:智能客服、虚拟助手、多轮对话机器人等。例如,ChatGPT、文心一言等对话机器人,能够理解用户的自然语言提问,并给出连贯、准确的回答。
- 专业领域应用:法律咨询(合同审核、法律条文解读)、医疗辅助(病历分析、疾病问诊)、教育辅导(知识点讲解、作业批改)、金融分析(市场趋势预测、财报解读)等。
- 多模态交互:结合图像、语音、视频等模态,实现跨模态理解和生成。例如,GPT-5可根据图像内容生成描述文本,或根据文本指令生成图像(需结合图像生成模型)。
5.4 挑战与发展趋势
尽管LLM取得了巨大成功,但仍面临诸多主要挑战:
- 幻觉(Hallucination)问题:模型可能生成看似合理但与事实不符的内容,这在专业领域(如医疗、法律)应用中存在较大风险。
- 计算成本高昂:LLM的预训练和微调需要大量的计算资源(如GPU集群),训练一次万亿参数模型的成本可达数百万美元,限制了中小机构的研究和应用。
- 上下文窗口限制:早期LLM的上下文窗口较小(如GPT-3为2048 token),难以处理长文本(如书籍、长文档),虽然当前模型的上下文窗口已扩展至百万token级别,但长文本处理的效率和准确性仍需优化。
- 安全性与伦理问题:可能被用于生成恶意内容(如虚假信息、垃圾邮件、恶意代码),同时存在隐私泄露风险(如记忆训练数据中的敏感信息)。
- 可解释性差:LLM的决策过程是“黑箱”,难以解释模型为何生成某个结果,这在需要可追溯性的场景(如医疗、法律)中是重要障碍。
与此同时,LLM也呈现出明确的未来发展趋势:
- 多模态融合:从单一文本模态向文本、图像、语音、视频、3D等多模态融合发展,实现更全面的感知和生成能力,贴近人类的多感官交互方式。
- 高效训练与推理:通过模型结构优化(如稀疏注意力、混合专家模型MoE)、量化训练、分布式训练框架升级等方式,降低LLM的计算成本,提升推理速度。
- 增强可解释性与可靠性:研究LLM的决策机制,引入知识图谱、逻辑推理规则等,提升模型的可解释性;通过对齐技术(如RLHF,基于人类反馈的强化学习)减少幻觉,提升输出的可靠性。
- 轻量化与个性化:发展小规模、高效的LLM(如7B、13B参数模型),适配边缘设备(如手机、物联网设备);通过个性化微调,让模型适配用户的特定需求和使用习惯。
- 知识增强与逻辑推理提升:将外部知识图谱、专业数据库融入LLM,增强模型的知识储备;通过优化预训练任务和微调策略,提升模型的逻辑推理能力(如数学推理、代码调试)。
- 安全与伦理规范建设:建立LLM的安全评估体系和伦理准则,研发恶意内容检测、隐私保护等技术,推动LLM的负责任发展。
大语言模型是Transformer架构的极致应用,通过大规模参数、海量预训练数据和高效学习范式,实现了自然语言处理能力的跨越式提升。作为深度学习与自然语言处理领域的核心方向,LLM的发展仍在加速,未来将在多模态融合、高效推理、知识增强等方面持续突破,推动人工智能技术更广泛地应用于社会生产生活的各个领域。
okok